I have a df like:
df = pd.DataFrame({'Animal': ['Falcon', 'Falcon',
'Parrot', 'Parrot','Elephant','Elephant','Elephant'],
'Max Speed': [380, 370, 24, 26,5,7,3]})
I would like to groupby Animal.
if I do in a notebook:
a = df.groupby(['Animal'])
display(a)
I get:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7f945bdd7b80>
I expected something like:
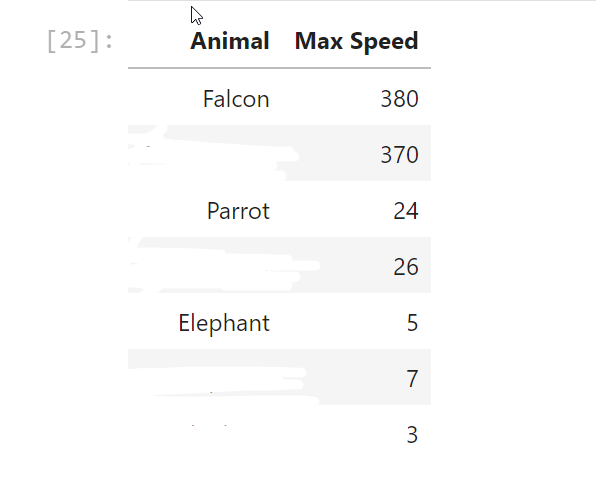
What I ultimate want to do is sort the df by number of animal appearances (Elephant 3, falcon 2 etc)
CodePudding user response:
You need check DataFrame.groupby:
Group DataFrame using a mapper or by a Series of columns.
So it is not for remove duplicates values by column, but for aggregation.
If need remove duplicated vales, set to empty string use:
df.loc[df['Animal'].duplicated(), 'Animal'] = ''
print (df)
Animal Max Speed
0 Falcon 380
1 370
2 Parrot 24
3 26
4 Elephant 5
5 7
6 3
If need groupby:
for i, g in df.groupby(['Animal']):
print (g)
Animal Max Speed
4 Elephant 5
5 Elephant 7
6 Elephant 3
Animal Max Speed
0 Falcon 380
1 Falcon 370
Animal Max Speed
2 Parrot 24
3 Parrot 26
CodePudding user response:
The groupby object requires an action, like a max or a min. This will result in two things:
- A regular pandas data frame
- The grouping key appearing once
You clearly expect both of the Falcon entries to remain so you don't actually want to do a groupby. If you want to see the entries with repeated animal values hidden, you would do that by setting the Animal column as the index. I say that because your input data frame is already in the order you wanted to display.
CodePudding user response:
Use mask:
>>> df.assign(Animal=df['Animal'].mask(df['Animal'].duplicated(), ''))
Animal Max Speed
0 Falcon 380
1 370
2 Parrot 24
3 26
4 Elephant 5
5 7
6 3
>>>
Or as index:
df.assign(Animal=df['Animal'].mask(df['Animal'].duplicated(), '')).set_index('Animal')
Max Speed
Animal
Falcon 380
370
Parrot 24
26
Elephant 5
7
3
>>>