In the TFX pipelines, how do we make use of BulkInferrer?
It is quite standard to connect the BulkInferrer with a trained model or pushed_model. However, what if I don't want to train the model again, instead I would love to use a previously trained model or pushed_model and use the BulkInferrer for batch inference(kinda like serving with BulkInferrer). Is it possible to do that?
If not, what is the purpose of BulkInferrer component, just to do a one-time prediction or validation after the whole training?
Any suggestions or comments will be appreciated, thanks.
CodePudding user response:
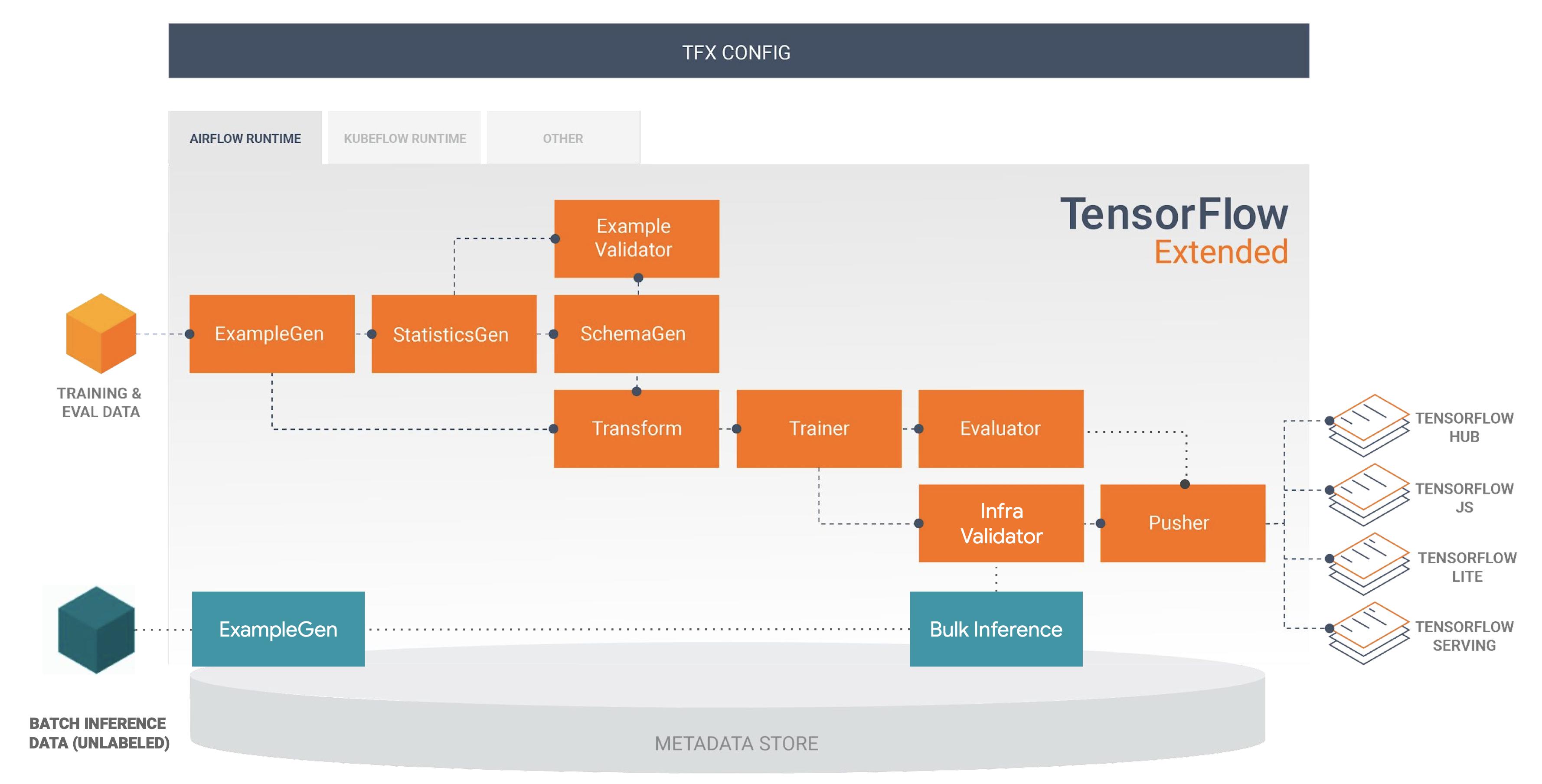 Robert Crowe nicely positioned BulkInferrer in the inference pipeline, during the recent BEAM summit
Robert Crowe nicely positioned BulkInferrer in the inference pipeline, during the recent BEAM summit
Here is a list of use cases of why would someone use the BulkInferrer, trying to approach it in the case of ml-pipelines rather than data-pipelines:
- Periodically in an batch job, such as a nightly run to infer scores for the data received last day. For example when the inference latency is high and needs to run offline to populate a cache with scores, or when large amount of instanced need to be inferred.
- When the inference results are not expected to be served directly back to the inference request (ie real-time) but can be executed asynchronously. For example, to shadow test a new model prior to its release.
- In an event-driven fashion. For example, trigger a model retraining when inferring batches of data to and model drift is detected.
- For cost optimisation. For example on low throughput models/services there might be long idle times of cpu/gpu instances.
To do this in your ML pipeline without retraining your model, you can include BulkInferrer indeed at the end of the pipeline and reuse the results from previous runs if the inputs and configuration has not changed. This is achieved by both Argo and Tekton workflow managers on Kubeflow pipelines, as they implement TFX, see step caching.