I am creating a table in Athena using below scripts
CREATE EXTERNAL TABLE `itcfmetadata`(
`itcf id` string,
`itcf control name` string,
`itcf control description` string,
`itcf process` string,
`standard` string,
`controlid` string,
`threshold` string,
`status` string,
`date reported` string,
`remediation (accs specific)` string,
`aws account id` string,
`aws resource id` string,
`aws account owner` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION
's3://itcfmetadata/'
TBLPROPERTIES (
'skip.header.line.count'='1');
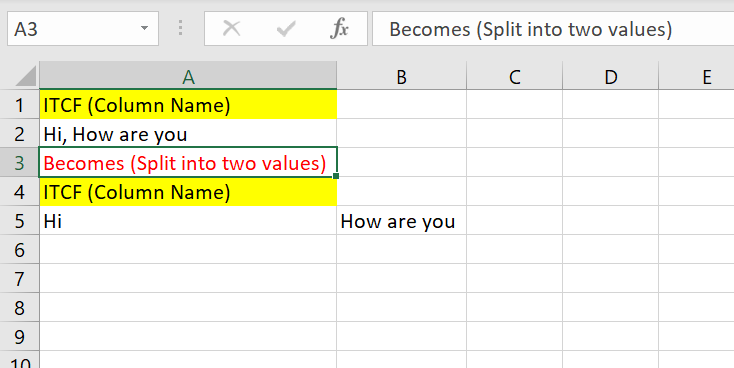
The S3 source file is csv file. This file is converted from a excel file and this csv file doe snot have comma seperated values, it is more like a excel file. Problem is when any column contains text like "Hi, How are you". It get split into two as there is a comma and "Hi" and "How are you" becomes two value and get split into two rows. How to avoid this using above create scripts ?
CSV File :
CodePudding user response:
Try using
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
instead of DELIMITED
The DELIMITED deserializer just looks at the delimiters you provide. The csv deserializet will only use those outside a pair of double quotes ".
See the docs: https://docs.aws.amazon.com/athena/latest/ug/csv-serde.html