I'm trying to split a date column in a pandas data frame using add_datepart( ).
trainingSetFirstCycle = pandas.read_csv(
"C:/Users/henri/OneDrive/Dokumente/Berufseinstieg/Sprachtechnologie/Predicting_Bike_Rental_Demand/Datasets/train_datetime_split.csv",
low_memory=False, parse_dates=["date"])
trainingSetFirstCycle.rent_count = numpy.log(trainingSetFirstCycle.rent_count)
trainingSetFirstCycle
date time season ... casual registered rent_count
0 2011-01-01 00:00:00 1 ... 3 13 2.772589
1 2011-01-01 01:00:00 1 ... 8 32 3.688879
2 2011-01-01 02:00:00 1 ... 5 27 3.465736
3 2011-01-01 03:00:00 1 ... 3 10 2.564949
4 2011-01-01 04:00:00 1 ... 0 1 0.000000
... ... ... ... ... ... ...
10881 2012-12-19 19:00:00 4 ... 7 329 5.817111
10882 2012-12-19 20:00:00 4 ... 10 231 5.484797
10883 2012-12-19 21:00:00 4 ... 4 164 5.123964
10884 2012-12-19 22:00:00 4 ... 12 117 4.859812
10885 2012-12-19 23:00:00 4 ... 4 84 4.477337
[10886 rows x 13 columns]
trainingSetFirstCycle.dtypes
date datetime64[ns]
However, running trainingSetFirstCycle = add_datepart(trainingSetFirstCycle, trainingSetFirstCycle.date, drop=True) returns this error message:
raise KeyError(f"None of [{key}] are in the [{axis_name}]")
KeyError: "None of [DatetimeIndex(['2011-01-01 00:00:00', '2011-01-01 01:00:00',\n ... dtype='datetime64[ns]', length=10886, freq=None)] are in the [columns]"
I checked the documentation to see what I'd done wrong.
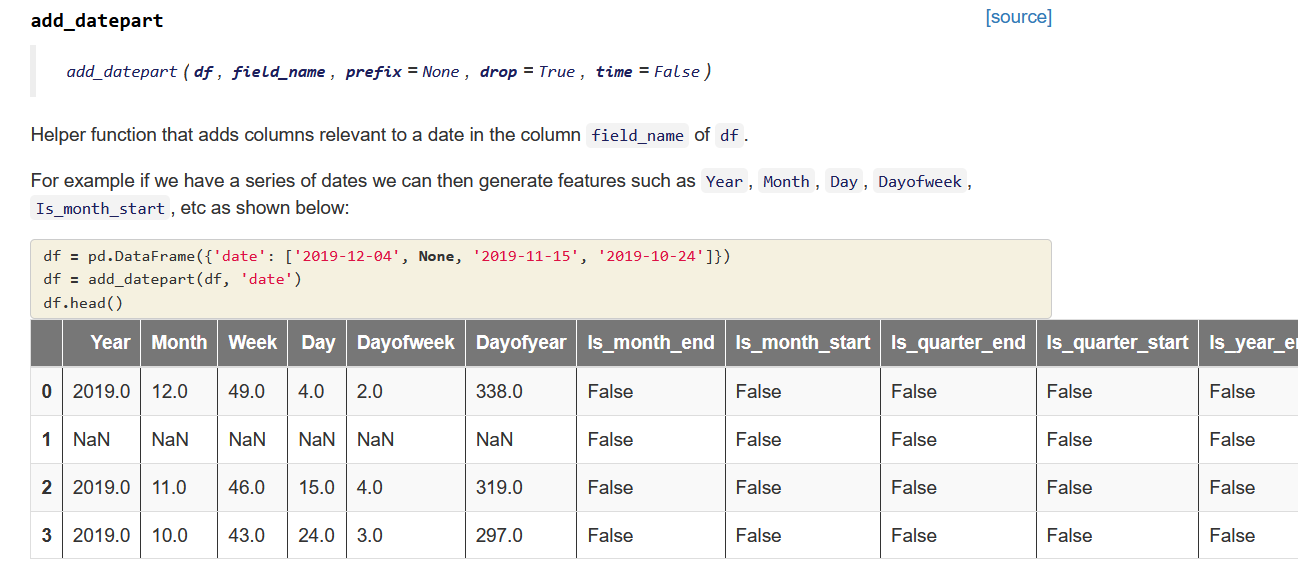
In the example shown, the definition of the data frame includes a dictionary consisting of the column name "date" and a list containing its first four values. So I reproduced this in my own data frame:
trainingSetFirstCycle = pandas.read_csv(
"C:/Users/henri/OneDrive/Dokumente/Berufseinstieg/Sprachtechnologie/Predicting_Bike_Rental_Demand/Datasets/train_datetime_split.csv",
{'date': ['2011-01-01', '2011-01-01 ', '2011-01-01', '2011-01-01']}, low_memory=False, parse_dates=["date"])
The result was this error message:
AttributeError: 'dict' object has no attribute 'encode'.
So, do you have an idea what it is I'm missing here? Thanks in advance.
CodePudding user response:
Solved by rewording the parameter "date"
This has been a semantic bug. Python failed to compile trainingSetFirstCycle = add_datepart(trainingSetFirstCycle, trainingSetFirstCycle.date, drop=True) because it didn't realize that trainingSetFirstCycle.date was supposed to be the column's name. I changed the parameter to simply "date", which has solved the problem.
Apparently, my misconception was that whenever you give a data frame column as a parameter to a function, you have to refer to it as df.column , because that was the syntax of the function numpy.log(trainingSetFirstCycle.rent_count), where the data frame column "rent_count", is the parameter of the function numpy.log.