I am reading a folder in adls in azure databricks which has sub folders containing parquet files.
path - base_folder/filename/
filename has subfolders like 2020, 2021 and these folders again have subfolders for month and day.
So path for actual parquet file is like - base_folder/filename/2020/12/01/part11111.parquet.
I am getting below error if I give a base folder path.

I have tried commands in below tread as well but it is showing same error.
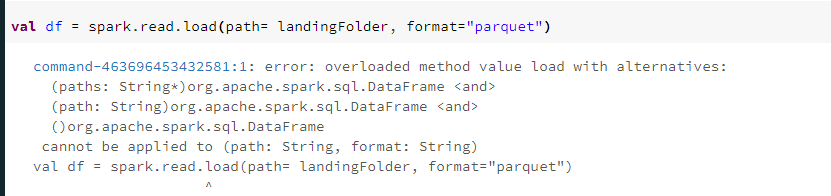
Please help me to read all parquet files in all sub folders in one dataframe.
CodePudding user response:
Your first error:
Unable to infer schema for Parquetusually happens when you try to read an empty directory as parquet. You can specify*in your path and it will go through subdirectories, take a look here: Reading parquet files from multiple directories in Pyspark.Second error: You are using Scala API, and the example you've provided is in Python.
DataFrameReaderAPI is different. Ref: Scala - DataFrameReader - Python - DataFrameReader
Try with:
spark.read.format("parquet").load(landingFolder)
as specified here: Generic Load/Save Functions