I have been struggling with a code because I haven't been able to remove or replace the stopwords of a list. I know I might be overlooking something but I can't figure out what it is.
Here is my list:
result = [' COLOMBIA Y LA NUEVA REVOLUCIÓN INDUSTRIAL Propuestas del Foco de Tecnologías Convergentes e Industrias Volumen COLOMBIA Artista Federico Uribe Propuestas del Foco de Tecnologías Convergentes e Industrias Tomo COLOMBIA Y LA NUEVA REVOLUCIÓN INDUSTRIAL Vicepresidencia de la República de Colombia Ministerio de Ciencia Tecnología e Innovación Elías D Niño Ruiz Jean Paul Allain José Alejandro Montoya Juan Luis Mejía Arango Markus Eisenhauer María del Pilar Noriega E Mauricio Arroyave Franco Mónica Álvarez Láinez Nora Cadavid Giraldo Olga L Quintero Montoya Orlando Ayala Raimundo Abello Tim Osswald Primera edición ISBN Impreso ISBN digital DOI https doi org vdyc Colección Misión Internacional de Sabios Título del volumen Colombia y la nueva revolución industrial Preparación editorial Universidad EAFIT Universidad del Norte Carrera No sur Dirección de Investigación Desarrollo e Innovación Tel Medellín Km Vía Puerto Colombia Área Metropolitana de Barranquilla e mail publicaciones eafit edu co Tel e mail dip uninorte edu co Corrección de textos y coordinación editorial Cristian Suárez Giraldo y Óscar Caicedo Alarcón Diseño de la colección y cubierta leonardofernandezsuarez com Diagramación Ana Milena Gómez Correa Medellín Colombia Prohibida la reproducción total o parcial por cualquier medio sin la autorización escrita del titular de los derechos patrimoniales __________________________________ Colombia y la nueva revolución industrial Elías D Niño Ruiz et al Medellín Colombia ', ' Yordan Mantilla uno de sus líderes señaló que actualmente se desarrollan en el mercado eléctrico y en sus proyectos de automatización requieren nuevas tecnologías de las comunicaciones p p Enfocamos el desarrollo del concepto de ciudades inteligentes creando soluciones para la cuantificación de variables ambientales Otro proyecto es T Cyborg que busca integrar el análisis de los sonidos de las ciudades para entender cómo percibe e interpreta su ciudad una persona ciega explicó Mantilla p p Insegroup tiene una unidad de negocio que busca desarrollar los pilotos de sus proyectos en Cúcuta para poner en práctica su oferta de servicios y ofrecerla a mediano plazo a nivel mundial p p strong Dentro de la validación del T Cyborg Latinoamérica y Centroamérica mostraron tener un potencial enorme para acceder a esa tecnología la cual es de punta e innovadora indicó el empresario strong p p Camilo Puello cofundador de Just Sapiens convirtió una idea de negocio digital nacida en en una empresa Hoy su iniciativa se ha vendido a nivel regional y nacional p p En un par de meses buscamos vender la idea a nivel internacional en el departamento hemos vendido el servicio a abogados y a entidades públicas En el país hemos llegado a Neiva Santa Marta y Bogotá explicó Puello p p A través del clúster se están desarrollando estrategias para enfocar a las empresas en segmentos de mercado con baja ocupación donde la región con su portafolio de servicio puede apoyar en la generación de alto valor agregado con soluciones TIC p p strong Vitrina internacional strong p p Una delegación de cerca de empresas colombianas en las que no se incluía empresas nortesantandereanas generó en el Mobile World Congress llevado a cabo en Barcelona ventas por cerca de millones de euros y expectativas de negocio de cerca de millones de euros p p Procolombia reseñó esta información en su página web donde se aseguró que Colombia despuntó en Barcelona siendo la delegación Latinoamericana más grande p p La presidenta de Procolombia Flavia Santoro manifestó que el Mobile World Congress fue una gran oportunidad para mostrarle al mundo el valor agregado de las industrias del país ']
Here are the codes I have tried:
for i in range(len(result)):
for j in stop_words:
if j in result[i]:
result[i] = result[i].replace(j, '')
and:
new_list=[]
for w in result:
w = w.lower()
if w not in stop_words:
new_list.append(w)
print("\n Palabras filtradas:",new_list)
but both of them show me this when I printed it:
['colombia y la nueva revolución industrial pr fc tcgí cvrg ir vl colombia ar frc urb pr fc tcgí cvrg ir t colombia y la nueva revolución industrial vcrc rúbc cb mr cc tcgí icó elí d nñ rz j p al jé ajr m j l mjí arg mrk er mrí pr nrg e mrc arrv frc móc álrz láz nr cv gl olg l qr m or a r ab t owl pr có isbn ir isbn gl doi rg vc cccó mó ircl sb tí vl cb rvlcó rl prcó rl uvr eafit uvr nr crr n r dccó ivgcó drrl icó t mlí k ví pr cb ár mr brrql l bcc f c t l r c crrccó crcó rl cr sárz gl ócr cc arcó dñ cccó cbr rrzrz c dgrcó a m góz crr mlí cb prb rrccó l rcl r qr rzcó cr r rc rl __________________________________ cb rvlcó rl elí d nñ rz l mlí cb mr cc tcgí icó mó ircl sb isbn eccó cb eccó rrl cb drrl cífc clógc cb i nñ rz e d ii nrg e mrí pr iii mjí arg j l iv ab l r v tí vi sr c c uvr ef cr crl bbc l ecrrí vlg ___________________________________ t colombia y la nueva revolución industrial bgí bcí m ab slv rr crr cr sr frc p r u ezb h mb trr eb mr rl eñ mc e frc lgr wj a grá pv cc bác ec mé wr lrr crr crz d brá srg hrc frc r nb a mrí r a a j c vl cc scl drrl h c eq c frr p crr a mrí arj sr vcr alr slg w m e u s d frc j sc h k sg n cr sr cc v
sl j m a crr nb mñz ib mg frc rlf lá jrg rl ajr j ergí sb j bv crr ag wlk ', ' rg cc r cr cgí c flr q r cífc vlcr fc r pr rr c cr á q í rc c c cc c cb méxc arg brl c gráfc r cbrcó rcl ár ir cb f ebrcó r r frcó wos cb rvlcó rl gráfc p r lí rbj r f ec brl cb lí c rvlcó cb rvlcó rl ccó bcc cb rc rgr u rg vg
jrcc bbrí có c bcc céc rccó cc rz rgr vcó l fr lens rg gr b c b céc r ccr c rccó cé c gcó cgí é fr uz fr fcó úr vc r c rbj céc vc cb rcl rfr ác fc vr tb e r r rccó cb í b c brg rccó cc r vc r g rccó rccó e r c cl
á rvc l áx vgr í rc cc r c éx tb ic rccó céc gcó l
prcj prccó crccó cc r prccó gcó f ebrcó r r frcó l rv gbl arccó r g cr rcv l rcl fccó vgcó có gr c cc c có c r fc rá gcó cc crczcó r ccó e cb lí c rvlcó rc vr r e cr fl l frcó r ccó crb rccó r gcó rcó cc cb s c gr v có rcó clógc r cfr vró cc cgí c vlcr icó rcó clógc r r clcc c r cb cg c r r c l r clcc d fr c bl cr fcrr rvc r
l r c r rc r d or fl á r v rcó clógc gr r q cfc c ñ r kz l tb r c v ár c cbrgr ccó b r c c l r rcr r c gú cfr mr crc ir tr cr ñ r m rr bc rcv crb c í r prc ir br ncl mcrc e v rcó r r cl fr g cróc bé í p d c mtic r v r g c cr v g á el v có c gbrl á l rvé c t r r p
fc có cb rvlcó rl vz gr r jr c c cb rcv gbl í el p críc r bj v r có r r u r á gr r crrr brc ccó c gr cñí sgú mcrc p cb c rc r grg rbjr gr r e frcó rc rfxó r c rzr c rá fcr cv act í d cb crrr brc rgl brc gr r p cr r rcó cr rcv cr céc ivró có cc cgí l r cb rr rvé ec cl có dane vr acti á bl tb arcó cgí r ñ r cb pr tcgí ncl gr p mcr ifrrcr cbrgr ccó b prc ir c rbóc iró d r l drbcó bg igc rfcl bckc f t kz cb lí c rvlcó l q l vró l cl c lr tb tb prccó cr r fccó cv acti cb t có t ic ccó rr er cr vgcó rrl clógc e gbrl ipsfl l rvc r hl clíc ong cc grc rl tl l l cop f t oct cálc oct cfr rvl cfr rc scr rcv c tcgí cvrg nbic ir cb c cóc l c fcr rvc dane b r cc cí í el jrcc r rccó bcr á rc c ár fc rcó c l v gr r grg e cr fcrr cr cb rvlcó rl g bcr rc frác cróc óc q écrc qr q c víc r rlq rlq pr c cr rvc clr rrl frác rc cv rl cífc écc l tb c frcó ']
CodePudding user response:
I think you need to split your text into tokens ("tokenize"), because the for w in result does not iterate over words but characters!
So it removes the characters that are stopwords.
As @Mahrkeenerh commented, you can try:
for w in result.split(): # For simple tokenization
w = w.lower()
if w not in stop_words:
new_list.append(w)
CodePudding user response:
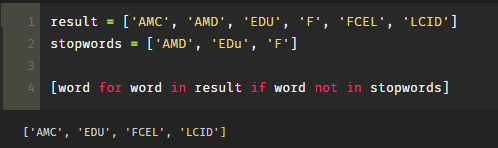
Try this [word for word in result if word not in stopwords]