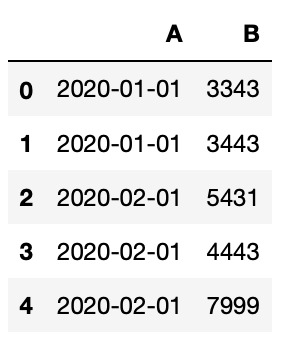
I have a dataframe with the following structure:
import pandas as pd
import numpy as np
from datetime import datetime
df = pd.DataFrame(
[
[datetime(2020, 1, 1), 3343],
[datetime(2020, 1, 1), 3443],
[datetime(2020, 2, 1), 5431],
[datetime(2020, 2, 1), 4443],
[datetime(2020, 2, 1), 7999],
],
columns=["A", "B"],
)
I want to add a new column to the dataframe, that shows the order position for each column A, considering the ordering parameter the column B.
Thus, the result of the previous dataframe would be:
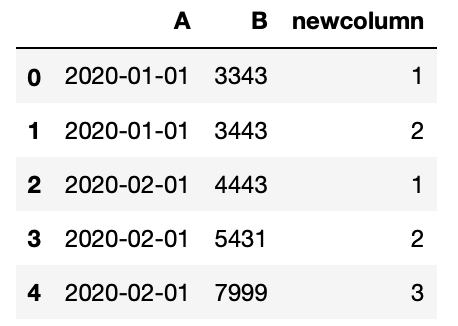
The goal is to do it in an efficient way, not using for loops.
CodePudding user response:
Use groupby rank.
df['new_column'] = df.groupby('A')['B'].rank(method='dense').astype(int)
Or as @АлексейР suggested, first sort the DataFrame by 'B' and then use groupby cumcount.
df = df.sort_values(['A', 'B'])
df['new_column'] = df.groupby('A').cumcount() 1