I have below dataset
I want to perform mean operation on 'horsepower' column after doing group by on column 'cylinders' and 'model year' using panda. I am running code in jupyter notebook.
Below is my code:
df = pd.read_csv('auto_mpg.csv')
df.groupby(['cylinders','model year']).agg({'horsepower':'mean'})
Basically, I am performing first group by on column 'cylinders' and 'model year' and then performing aggregation operation to get mean value. I am getting below error:
DataError Traceback (most recent call last)
<ipython-input-105-967f7e0151c3> in <module>
2 #Creating a DataFrame grouped on cylinders and model_year and finding mean, min and max of horsepower
3 df = pd.read_csv('auto_mpg.csv')
----> 4 df.groupby(['cylinders','model year']).agg({'horsepower':['mean']})
~\anaconda3\lib\site-packages\pandas\core\groupby\generic.py in aggregate(self, func, engine, engine_kwargs, *args, **kwargs)
949 func = maybe_mangle_lambdas(func)
950
--> 951 result, how = self._aggregate(func, *args, **kwargs)
952 if how is None:
953 return result
~\anaconda3\lib\site-packages\pandas\core\base.py in _aggregate(self, arg, *args, **kwargs)
414
415 try:
--> 416 result = _agg(arg, _agg_1dim)
417 except SpecificationError:
418
~\anaconda3\lib\site-packages\pandas\core\base.py in _agg(arg, func)
381 result = {}
382 for fname, agg_how in arg.items():
--> 383 result[fname] = func(fname, agg_how)
384 return result
385
~\anaconda3\lib\site-packages\pandas\core\base.py in _agg_1dim(name, how, subset)
365 "nested dictionary is ambiguous in aggregation"
366 )
--> 367 return colg.aggregate(how)
368
369 def _agg_2dim(how):
~\anaconda3\lib\site-packages\pandas\core\groupby\generic.py in aggregate(self, func, engine, engine_kwargs, *args, **kwargs)
244 # but not the class list / tuple itself.
245 func = maybe_mangle_lambdas(func)
--> 246 ret = self._aggregate_multiple_funcs(func)
247 if relabeling:
248 ret.columns = columns
~\anaconda3\lib\site-packages\pandas\core\groupby\generic.py in _aggregate_multiple_funcs(self, arg)
317 obj._reset_cache()
318 obj._selection = name
--> 319 results[base.OutputKey(label=name, position=idx)] = obj.aggregate(func)
320
321 if any(isinstance(x, DataFrame) for x in results.values()):
~\anaconda3\lib\site-packages\pandas\core\groupby\generic.py in aggregate(self, func, engine, engine_kwargs, *args, **kwargs)
238
239 if isinstance(func, str):
--> 240 return getattr(self, func)(*args, **kwargs)
241
242 elif isinstance(func, abc.Iterable):
~\anaconda3\lib\site-packages\pandas\core\groupby\groupby.py in mean(self, numeric_only)
1391 Name: B, dtype: float64
1392 """
-> 1393 return self._cython_agg_general(
1394 "mean",
1395 alt=lambda x, axis: Series(x).mean(numeric_only=numeric_only),
~\anaconda3\lib\site-packages\pandas\core\groupby\groupby.py in _cython_agg_general(self, how, alt, numeric_only, min_count)
1049
1050 if len(output) == 0:
-> 1051 raise DataError("No numeric types to aggregate")
1052
1053 return self._wrap_aggregated_output(output, index=self.grouper.result_index)
DataError: No numeric types to aggregate
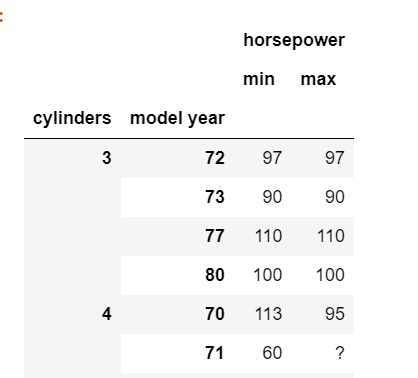
While I get min and max aggregation on 'horsepower' column successfully.
df = pd.read_csv('auto_mpg.csv')
df.groupby(['cylinders','model year']).agg({'horsepower':['min','max']})
CodePudding user response:
Check the data type. I see the root cause error at the bottom of your post:
raise DataError("No numeric types to aggregate")
CodePudding user response:
Put that ‘mean’ into bracket then, if data type is right:
agg({'horsepower': ['mean']})
CodePudding user response:
I loaded the auto-mpg the dataset from https://www.kaggle.com/uciml/autompg-dataset/version/3nd
and managed to replicate the problem.
The root cause is that horsepower column is loaded as type object with missing values represented as question mark strings (?), for example:
df[df.horsepower.str.contains("\?")]
Pandas doesn't know how to take the mean of question marks, so the solution would be casting the column to float:
# Convert non digit strings to NaN
df.loc[~df.horsepower.str.isdigit(), "horsepower"] = np.NaN
# Cast to float
df.horsepower = df.horsepower.astype("float")
# Aggregate
df.groupby(["cylinders", "model year"]).agg({"horsepower": "mean"})
Used pandas==1.1.5 and numpy==1.19.5.
CodePudding user response:
Try this
df = pd.read_csv('auto_mpg.csv')
df.groupby(['cylinders','model year']).mean()["horsepower]
df.groupby(['cylinders','model year']).mean() will give you the mean of each column and then you are selecting the horsepower variable to get the desired columns from the df on which groupby and mean operations were performed.