So I have this dataframe. The columns 'Time' follows a sequence where there are all weeks that fall between the first and the last rows populated in the column. But one of the values i.e. W43-2021 is missing.
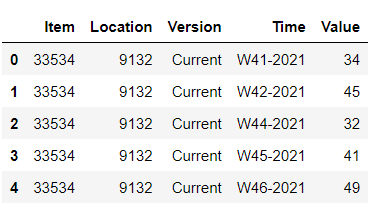
How do I insert a new row corresponding to W43-2021 with all the other column values be either same as others or None and 'Values' as 0. Basically like the below dataframe.
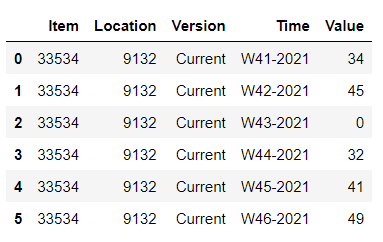
I have tried tried below approach to solve this problem.
f = int(df['Time.[Week]'][0][1:3])
l = int(df['Time.[Week]'].iloc[-1][1:3])
check = list(df['Time.[Week]'].str[1:3])
check = list(map(int, check))
c = []
for i in range(f, l 1):
if i not in check:
c.append(i)
for week in c:
temp_df = pd.DataFrame(columns = df.columns)
temp_df.loc[0, 'Time.[Week]'] = 'W' str(week) '-2021'
df.append(temp_df)
This doesn't seem to be the most appropriate way of dealing with the issue as order is getting broken due to appending dataframe at the end and there could be multiple missing rows which could problem later. What could be a better and more pythonic way of handling this case?
Also find the code to initiate the df if required.
df = pd.DataFrame([[33534,9132,'Current','W41-2021',34],
[33534,9132,'Current','W42-2021', 45],
[33534,9132,'Current','W44-2021', 32],
[33534,9132,'Current','W45-2021', 41],
[33534,9132,'Current','W46-2021',49]], columns = ['Item', 'Location', 'Version', 'Time', 'Value'])
CodePudding user response:
You can use the following:
# build missing values
weeks = df['Time'].str.extract('(?<=W)(\d )').astype(int)
idx = [f'W{w}-2021' for w in range(weeks.min()[0], weeks.max()[0] 1)]
# add missing values
df2 = df.set_index('Time').reindex(idx).reset_index()
# ffill, except 'Value'
df2 = df2.combine_first(df2.drop(columns='Value').ffill())[df.columns]
output:
>>> df2
Item Location Version Time Value
0 33534.0 9132.0 Current W41-2021 34.0
1 33534.0 9132.0 Current W42-2021 45.0
2 33534.0 9132.0 Current W43-2021 NaN
3 33534.0 9132.0 Current W44-2021 32.0
4 33534.0 9132.0 Current W45-2021 41.0
5 33534.0 9132.0 Current W46-2021 49.0
CodePudding user response:
Use -
df['week'] = df['Time'].str[1:3].astype(int)
df2 = pd.DataFrame([ i for i in range(week.min(), week.max())], columns=['week']).merge(df, how='outer')
fill_val = df['Time'].iloc[0]
df2['Time'] = df2['Time'].fillna(fill_val[0] df2['week'].astype(str) fill_val[3:])
df2 = df2.fillna(0)
Output
week Time Value
0 41 W41-2021 34.0
1 42 W42-2021 45.0
2 43 W43-2021 0.0
3 44 W44-2021 32.0
4 45 W45-2021 41.0
5 46 W46-2021 49.0
CodePudding user response:
You can do like that:
Code:
df = pd.DataFrame([[33534,9132,'Current','W41-2021',34],
[33534,9132,'Current','W42-2021', 45],
[33534,9132,'Current','W44-2021', 32],
[33534,9132,'Current','W45-2021', 41],
[33534,9132,'Current','W46-2021',49]], columns = ['Item', 'Location', 'Version', 'Time', 'Value'])
new_df = df.copy(deep=True)
new_df = new_df.append(pd.DataFrame([[33534,9132,'Current','W43-2021',0]],columns=['Item', 'Location', 'Version', 'Time', 'Value']))
new_df = new_df.sort_values("Time",ascending=True)
print(new_df)
Because the time is ordered you can just append the new value and then sort the values according to the time.
Output:
Item Location Version Time Value
0 33534 9132 Current W41-2021 34
1 33534 9132 Current W42-2021 45
0 33534 9132 Current W43-2021 0
2 33534 9132 Current W44-2021 32
3 33534 9132 Current W45-2021 41
4 33534 9132 Current W46-2021 49