I have a pyspark dataframe that looks like the following,
data2 = [("James",["A x","B z","C q","D", "E"]),
("Michael",["A x","C","E","K", "D"]),
("Robert",["A y","R","B z","B","D"]),
("Maria",["X","A y","B z","F","B"]),
("Jen",["A","B","C q","F","R"])
]
df2 = spark.createDataFrame(data2, ["Name", "My_list" ])
df2
Name My_list
0 James [A x, B z, C q, D, E]
1 Michael [A x, C, E, K, D]
2 Robert [A y, R, B z, B, D]
3 Maria [X, A y, B z, F, B]
4 Jen [A, B, C q, F, R]
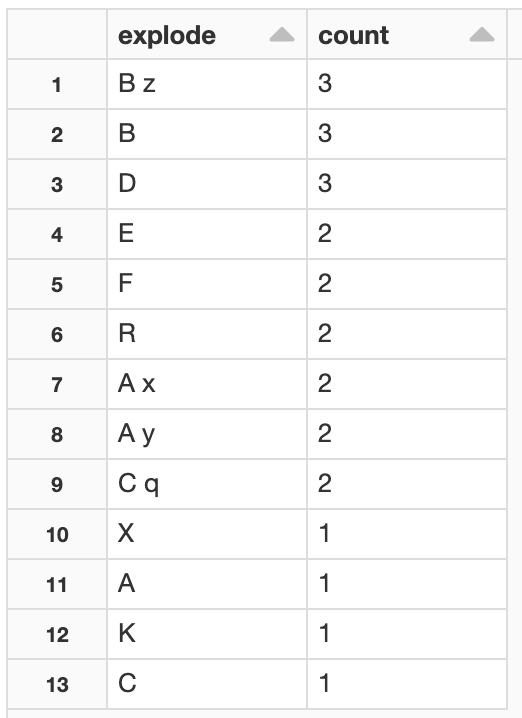
I want to be able to count the elements in the column 'My_list' and sort in descending order? For example,
'A x' appeared -> P times,
'B z' appeared -> Q times, and so on.
Can someone please put some lights on this? Thank you very much in advance.
CodePudding user response:
The following command explodes the array, and provides the count of each element
import pyspark.sql.functions as F
df_ans = (df2
.withColumn("explode", F.explode("My_list"))
.groupBy("explode")
.count()
.orderBy(F.desc("count"))
the result is