X_train = {my training data features}
y_train = {my training data truth}
kf = KFold(n_splits=5, random_state=42, shuffle=True)
score = cross_val_score(SVC(), X_train, y_train, scoring = 'accuracy', cv = kf, n_jobs = -1)
gives this:
array([1. , 0.98717949, 1. , 1. , 0.98701299])
I run this code to get AUC:
tprs = []
aucs = []
mean_fpr = np.linspace(0, 1, 100)
plt.figure(figsize=(10,10))
i = 0
for train, test in kf.split(npX_train):
model = SVC(probability=True).fit(npX_train[train], npy_train[train])
probas_ = model.predict_proba(npX_train[test])
# Compute ROC curve and area the curve
fpr, tpr, thresholds = roc_curve(npy_train[test], probas_[:, 1])
tprs.append(interp(mean_fpr, fpr, tpr))
tprs[-1][0] = 0.0
roc_auc = auc(fpr, tpr)
aucs.append(roc_auc)
plt.plot(fpr, tpr, lw=1, alpha=0.3,
label='ROC fold %d (AUC = %0.2f)' % (i, roc_auc))
i = 1
plt.plot([0, 1], [0, 1], linestyle='--', lw=2, color='r',
label='Chance', alpha=.8)
mean_tpr = np.mean(tprs, axis=0)
mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
std_auc = np.std(aucs)
plt.plot(mean_fpr, mean_tpr, color='b',
label=r'Mean ROC (AUC = %0.2f $\pm$ %0.2f)' % (mean_auc, std_auc),
lw=2, alpha=.8)
std_tpr = np.std(tprs, axis=0)
tprs_upper = np.minimum(mean_tpr std_tpr, 1)
tprs_lower = np.maximum(mean_tpr - std_tpr, 0)
plt.fill_between(mean_fpr, tprs_lower, tprs_upper, color='grey', alpha=.2,
label=r'$\pm$ 1 std. dev.')
plt.xlim([-0.01, 1.01])
plt.ylim([-0.01, 1.01])
plt.xlabel('False Positive Rate',fontsize=18)
plt.ylabel('True Positive Rate',fontsize=18)
plt.title('Cross-Validation ROC of SVM',fontsize=18)
plt.legend(loc="lower right", prop={'size': 15})
plt.show()
which gives me this:
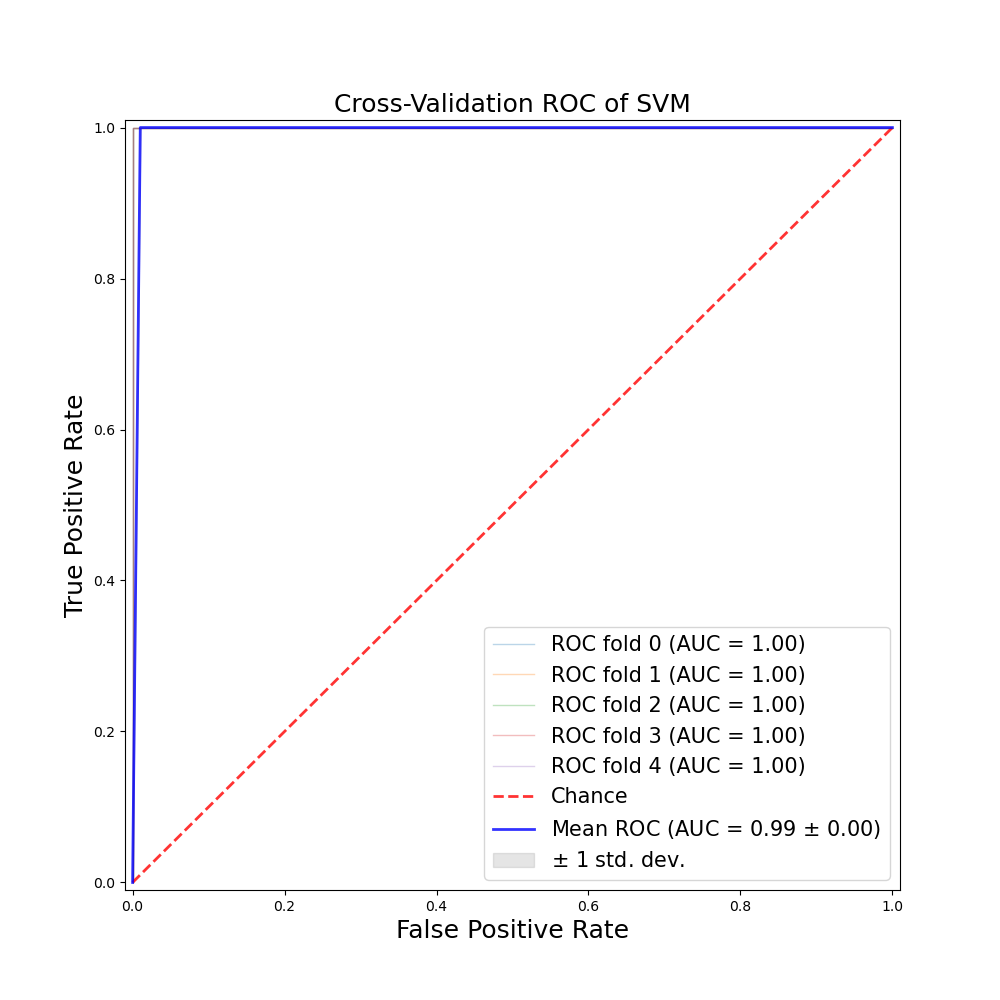
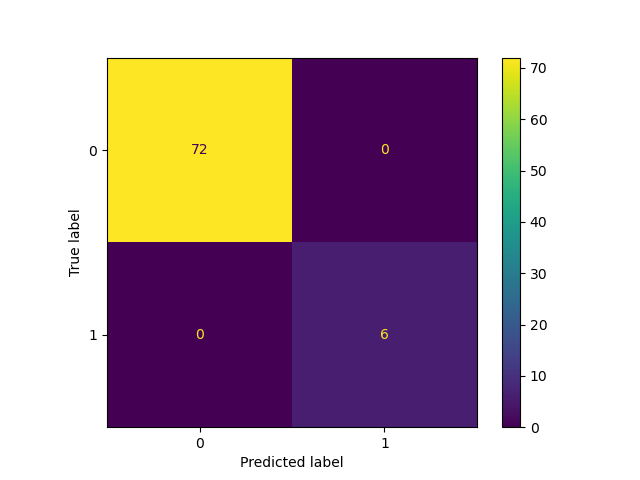
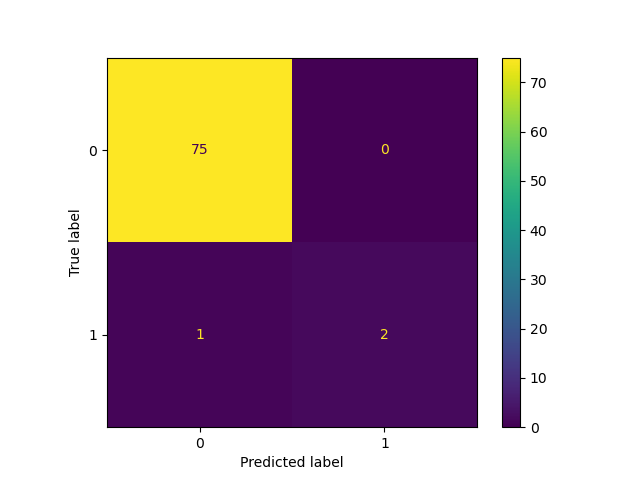
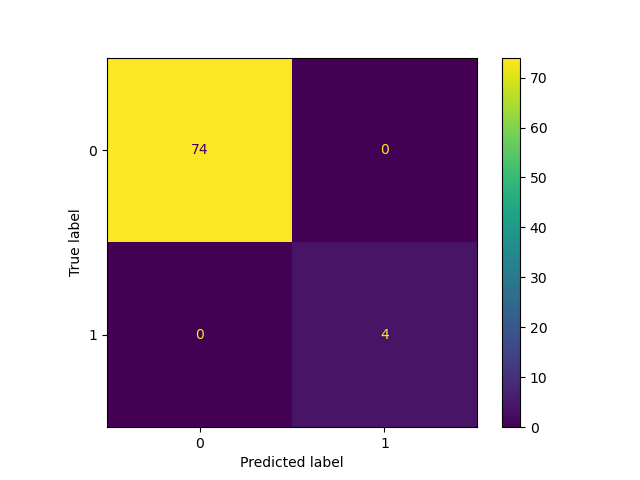
but if I get a confusion matrix for each iteration:
for train, test in kf.split(npX_train):
model = SVC(probability=True).fit(npX_train[train], npy_train[train])
# make confusion matrix plot for iteration
y_pred = model.predict(npX_train[test])
cm = confusion_matrix(npy_train[test], y_pred)
cm_display = ConfusionMatrixDisplay(cm).plot()
plot_confusion_matrix(model, npX_train[test], npy_train[test])
plt.plot()
The accuracy for label 1, which I care about does not look that great. Of the 22 true label 1, seems to get it right 20 times out of all runs.
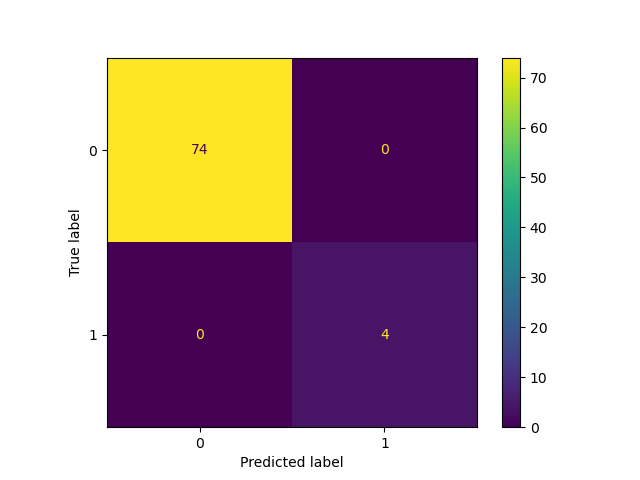
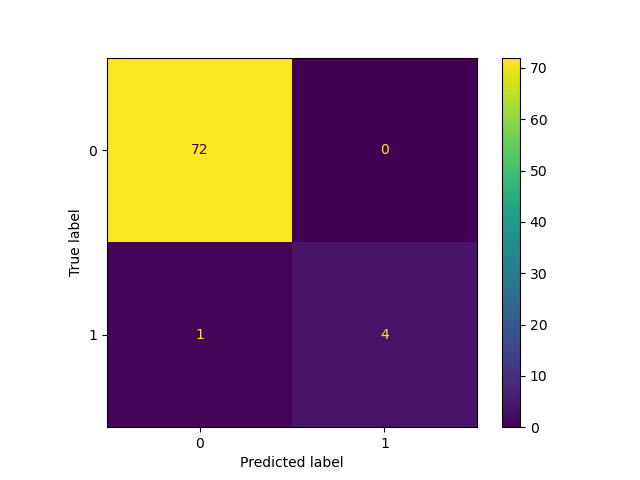
My questions are:
Did I mess up that AUC plot or is that slight bend in the blue mean ROC line reflecting the inaccuracy of the model?
Is there a better way to evaluate accuracy for a biased input where I care about the accurate prediction of the more rare event?
CodePudding user response:
For biased or imbalanced datasets use the metric F1 score. F1 score uses precision and recall.
Read for more detail on f1 score https://medium.com/analytics-vidhya/accuracy-vs-f1-score-6258237beca2
Sklearn https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html