I have accident data and part of this data includes the year of the accident, degree of injury and age of the injured person. this is an example of the DataFrame:
df = pd.DataFrame({'Year': ['2010', '2010','2010','2010','2010','2011','2011','2011','2011'],
'Degree_injury': ['no_injury', 'death', 'first_aid', 'minor_injury','disability','disability', 'disability', 'death','first_aid'],
'Age': [50,31,40,20,45,29,60,18,48]})
print(df)
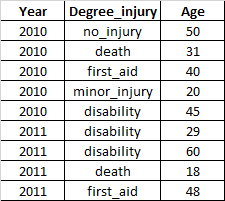
I want three output variables to be grouped in a table by year when the age is less than 40 and get counts for number of disabilities, number of deaths, and number of minor injuries.
The output should be like this:

I generated the three variables (num_disability, num_death, num_minor_injury) when the age is < 40 as shown below.
disability_filt = (df['Degree_injury'] =='disability') &\
(df['Age'] <40)
num_disability = df[disability_filt].groupby('Year')['Degree_injury'].count()
death_filt = (df['Degree_injury'] == 'death')& \
(df['Age'] <40)
num_death = df[death_filt].groupby('Year')['Degree_injury'].count()
minor_injury_filt = (df['Degree_injury'] == 'death') & \
(df['Age'] <40)
num_minor_injury = df[minor_injury_filt].groupby('Year')['Degree_injury'].count()
How to combine these variables in one table to be as illustrated in the above table?
Thank you in advance,
CodePudding user response:
Use pivot_table after filter your rows according your condition:
out = df[df['Age'].lt(40)].pivot_table(index='Year', columns='Degree_injury',
values='Age', aggfunc='count', fill_value=0)
print(out)
# Output:
Degree_injury death disability minor_injury
Year
2010 1 0 1
2011 1 1 0
CodePudding user response:
# prep data
df2 = df.loc[df.Age<40,].groupby("Year").Degree_injury.value_counts().to_frame().reset_index(level=0, inplace=False)
df2 = df2.rename(columns={'Degree_injury': 'Count'})
df2['Degree_injury'] = df2.index
df2
# Year Count Degree_injury
# death 2010 1 death
# minor_injury 2010 1 minor_injury
# death 2011 1 death
# disability 2011 1 disability
# pivot result
df2.pivot(index='Year',columns='Degree_injury')
# death disability minor_injury
# Year
# 2010 1.0 NaN 1.0
# 2011 1.0 1.0 NaN