I have practiced with plotly in R and created a barplot with data from a textbook called stats_test
prada_stats_test_url <- paste0("https://raw.github.com/",
"sebastiansauer/",
"Praxis_der_Datenanalyse/",
"master/",
"data/stats_test.csv")
stats_test <- read.csv(prada_stats_test_url)
Here is the code for the barplot:
test <- stats_test %>%
drop_na() %>%
ggplot()
aes(x = interest, fill = bestanden)
geom_bar(position = "fill")
test <- ggplotly(test)
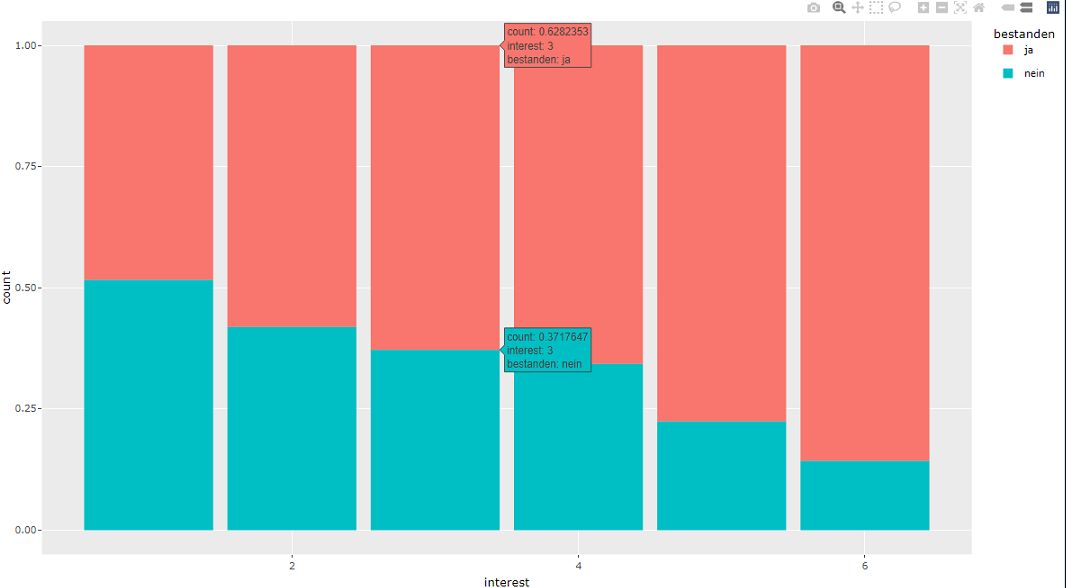
When I scroll over the graph it shows me the percentage ratios. I would like to round these to only two decimal places. How could I do that? And maybe add a percantage symbol.
Here is the output from the dataset dput(head(stats_test,20))
structure(list(row_number = 1:20, date_time = c("05.01.2017 13:57:01",
"05.01.2017 21:07:56", "05.01.2017 23:33:47", "06.01.2017 09:58:05",
"06.01.2017 14:13:08", "06.01.2017 14:21:18", "06.01.2017 14:25:49",
"06.01.2017 17:24:53", "07.01.2017 10:11:17", "07.01.2017 18:10:05",
"08.01.2017 12:56:43", "08.01.2017 19:17:20", "09.01.2017 09:51:37",
"09.01.2017 12:15:48", "09.01.2017 15:23:15", "09.01.2017 15:52:12",
"09.01.2017 20:49:48", "09.01.2017 22:57:38", "10.01.2017 17:16:48",
"10.01.2017 18:33:15"), bestanden = c("ja", "ja", "ja", "nein",
"ja", "ja", "ja", "nein", "ja", "ja", "ja", "ja", "nein", "ja",
"ja", "nein", "ja", "ja", "nein", "ja"), study_time = c(5L, 3L,
5L, 2L, 4L, NA, NA, 2L, 2L, 4L, 1L, 4L, 1L, 4L, NA, 2L, 2L, 3L,
NA, 3L), self_eval = c(8L, 7L, 10L, 3L, 8L, NA, NA, 5L, 3L, 5L,
2L, 7L, 2L, 9L, NA, 5L, 5L, 3L, NA, 5L), interest = c(5L, 3L,
6L, 2L, 6L, NA, NA, 3L, 5L, 5L, 4L, 4L, 2L, 3L, NA, 3L, 3L, 5L,
NA, 2L), score = c(29L, 29L, 40L, 18L, 34L, 39L, 40L, 24L, 25L,
33L, 32L, 31L, 22L, 35L, 30L, 24L, 33L, 32L, 22L, 26L)), row.names = c(NA,
20L), class = "data.frame")
CodePudding user response:
You can calculate the tooltip manually:
library(tidyverse)
library(plotly)
#>
#> Attaching package: 'plotly'
#> The following object is masked from 'package:ggplot2':
#>
#> last_plot
#> The following object is masked from 'package:stats':
#>
#> filter
#> The following object is masked from 'package:graphics':
#>
#> layout
prada_stats_test_url <- paste0(
"https://raw.github.com/",
"sebastiansauer/",
"Praxis_der_Datenanalyse/",
"master/",
"data/stats_test.csv"
)
stats_test <-
read.csv(prada_stats_test_url) %>%
drop_na() %>%
count(interest, bestanden) %>%
group_by(interest) %>%
mutate(
n = n / sum(n),
tooltip = (round(n * 100, 2)) %>% paste0("%")
)
stats_test
#> # A tibble: 12 x 4
#> # Groups: interest [6]
#> interest bestanden n tooltip
#> <int> <chr> <dbl> <chr>
#> 1 1 ja 0.8 80%
#> 2 1 nein 0.2 20%
#> 3 2 ja 0.851 85.11%
#> 4 2 nein 0.149 14.89%
#> 5 3 ja 0.803 80.3%
#> 6 3 nein 0.197 19.7%
#> 7 4 ja 0.829 82.93%
#> 8 4 nein 0.171 17.07%
#> 9 5 ja 0.911 91.11%
#> 10 5 nein 0.0889 8.89%
#> 11 6 ja 0.889 88.89%
#> 12 6 nein 0.111 11.11%
plt <-
stats_test %>%
ggplot()
aes(x = interest, y = n, fill = bestanden, tooltip = tooltip)
geom_bar(stat = "identity")
ggplotly(plt, tooltip = "tooltip")