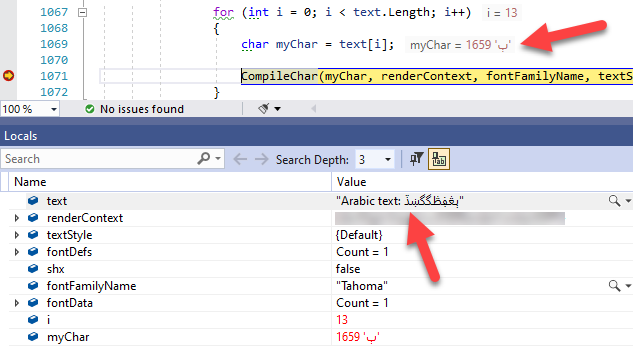
Why while I loop over every single char of this .NET C# string Arabic text: ٻڠڣڟگگښڏ at position 13th I get the wrong letter? 'ٻ' instead of 'ڏ'.
How do I fix it?
CodePudding user response:
Arabic is written right-to-left. The arrow points to the character at offset 20.
You're pointing to the last
0: U 0041 LATIN CAPITAL LETTER A
1: U 0072 LATIN SMALL LETTER R
2: U 0061 LATIN SMALL LETTER A
3: U 0062 LATIN SMALL LETTER B
4: U 0069 LATIN SMALL LETTER I
5: U 0063 LATIN SMALL LETTER C
6: U 0020 SPACE
7: U 0074 LATIN SMALL LETTER T
8: U 0065 LATIN SMALL LETTER E
9: U 0078 LATIN SMALL LETTER X
10: U 0074 LATIN SMALL LETTER T
11: U 003A COLON
12: U 0020 SPACE
13: U 067B ARABIC LETTER BEEH
14: U 06A0 ARABIC LETTER AIN WITH THREE DOTS ABOVE
15: U 06A3 ARABIC LETTER FEH WITH DOT BELOW
16: U 069F ARABIC LETTER TAH WITH THREE DOTS ABOVE
17: U 06AF ARABIC LETTER GAF
18: U 06AF ARABIC LETTER GAF
19: U 069A ARABIC LETTER SEEN WITH DOT BELOW AND DOT ABOVE
20: U 068F ARABIC LETTER DAL WITH THREE DOTS ABOVE DOWNWARDS
And that's not going into the fact that a grapheme (visual element) can be composed from multiple Unicode Code Points, and that C# uses surrogate pairs and thus multiple char values to represent some Unicode Code Points.
For example, there exists a script where the following grapheme exists: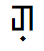
- The grapheme is formed from the Unicode Code Points U 11A0B followed by U 11A33.
- C# encodes U 11A0B as chars 0xD806 followed by 0xDE0B.
- C# encodes U 11A33 as chars 0xD806 followed by 0xDE33.
So the grapheme would be represented by the following sequence of four char values!
- 0xD806
- 0xDE0B
- 0xD806
- 0xDE33
And no, it's not just for archaic languages. "