I am having SQL query like this (will be parametrized once I make this work):
using (FbCommand cmd = new FbCommand("SELECT MAGACINID, ROBAID, SUM(KOLICINA) AS GOD" godina.ToString() " FROM STAVKA WHERE VRDOK = 13 OR VRDOK = 15 GROUP BY MAGACINID, ROBAID ORDER BY ROBAID", con))
{
using (FbDataAdapter da = new FbDataAdapter(cmd))
{
DataTable tempDT = new DataTable();
if (dt.Rows.Count == 0)
{
da.Fill(dt);
continue;
}
da.Fill(tempDT);
var result = dt.AsEnumerable()
.Join(tempDT.AsEnumerable(),
x => new { field1 = x["MAGACINID"], field2 = x["ROBAID"] },
y => new { field1 = y["MAGACINID"], field2 = y["ROBAID"] },
(x, y) => new {
x,
addYear = y["GOD" godina.ToString()]
});
dt = LINQResultToDataTable(result);
}
}
And here is LINQResultToDataTable() method
private DataTable LINQResultToDataTable<T>(IEnumerable<T> Linqlist)
{
DataTable dt = new DataTable();
PropertyInfo[] allColumns = null;
if (Linqlist == null) return dt;
foreach (T Record in Linqlist)
{
if (allColumns == null)
{
allColumns = ((Type)Record.GetType()).GetProperties();
// Record at position 0 is whole object and needs to be broke into pieces
// Record at position 1 is new column
foreach (PropertyInfo GetProperty in allColumns)
{
Type colType = GetProperty.PropertyType;
if ((colType.IsGenericType) && (colType.GetGenericTypeDefinition()
== typeof(Nullable<>)))
{
colType = colType.GetGenericArguments()[0];
}
dt.Columns.Add(new DataColumn(GetProperty.Name, colType));
}
}
DataRow dr = dt.NewRow();
foreach (PropertyInfo pinfo in allColumns)
{
dr[pinfo.Name] = pinfo.GetValue(Record, null) == null ? DBNull.Value : pinfo.GetValue
(Record, null);
}
dt.Rows.Add(dr);
}
return dt;
}
First datatable fill is okay and it fills it with these columns:
MagacinID
RobaID
God2021
Now when I try to join new table using linq I should only add God2020 as new column.
Problem is that when I am creating output of linq I cannot tell it to break x object into columns but I need to take it whole so linq result looks like this:
x (this one have ItemArray with all columns)
God2020
And new datatable looks same.
What I tried doing is inside LINQResultToDataTable method to take 0th element of Result and break it into columns, add to datatable, add new one (1st element) and populate it (see comment in that method) but I am stuck and do not know how to do that. Anyone have any solution?
Edit: I made it not clear so here is more explanation.
I have foreach loop which loops through 5 databases and inside that foreach loop is this code.
First database returns these columns
MagacinID
RobaID
God2021
Second
MagacinID
RobaID
God2020
Third
MagacinID
RobaID
God2019
Fourth
MagacinID
RobaID
God2018
Fifth
MagacinID
RobaID
God2017
I want all this merged into one datatable on columns MagacinID AND RobaID like this:
MagacinID
RobaID
God2021
God2020
God2019
God2018
God2017
CodePudding user response:
By Merge, I mean use the DataTable merge, which basically does something like a full outer join on declared PK fields in a datatable, and then makes the merged-into table the result of the join;
var d1 = new DataTable();
d1.Columns.Add("SomeId");
d1.Columns.Add("Col1");
d1.Rows.Add("ID1", "Col1Val1");
d1.Rows.Add("ID2", "Col1Val2");
d1.PrimaryKey = new[] { d1.Columns["SomeId"] };
var d2 = new DataTable();
d2.Columns.Add("SomeId");
d2.Columns.Add("Col2");
d2.Rows.Add("ID1", "Col2Val1");
d2.Rows.Add("ID3", "Col2Val2");
d2.PrimaryKey = new[] { d2.Columns["SomeId"] };
var d3 = new DataTable();
d3.Columns.Add("SomeId");
d3.Columns.Add("Col3");
d3.Rows.Add("ID2", "Col3Val1");
d3.Rows.Add("ID3", "Col3Val2");
d3.PrimaryKey = new[] { d3.Columns["SomeId"] };
d1.Merge(d2, false, MissingSchemaAction.Add);
d1.Merge(d3, false, MissingSchemaAction.Add);
Here's what the above code leads to:
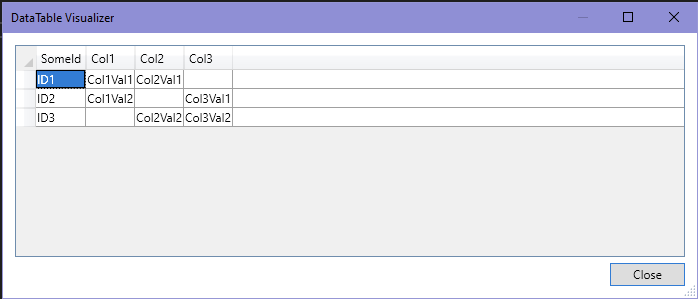
d1 started off with two columns, then during the first Merge it added in a third (Col2), and the values from d2's Col2 were put into d1's Col2, matching on the PK column (SomeId).
Then during the second Merge a fourth column was added to d1 (Col3), and the values out of Col3 in d3 copied into d1.
You'll notice that I deliberately made d2 have different PK values to d1, so not only do new columns get added, but new rows get added too
No new rows were added by this second merge op (d1 already had an ID1, ID2 and ID3)