I want to alter the Sankey plot I made using networkD3 R package so that multiple links flow from one node, here is what I did so far:
header of random sample of data:
Study Category Class
<chr> <chr> <chr>
1 study17 cat H class B;class C
2 study32 cat A;cat B class A
3 study7 cat F class A
4 study21 cat F class C
5 study24 cat F class B;class C
6 study15 cat E;cat K class C
# example data
d <- read.csv(text = "Study,Category,Class
study17,cat H,class B;class C
study32,cat A;cat B,class A
study7,cat F,class A
study21,cat F,class C
study24,cat F,class B;class C
study15,cat E;cat K,class C")
Using this 
However, as you can tell, the second and third columns now include "composite nodes" such as "cat A;cat B" and "class B; class C".
I would like to make it such that 2 nodes flow from study 32: one to cat A and one to cat B. Similarly, I would like two nodes flowing from cat F (row5): one to class B and one to class C.
In essence, I am asking if something like link splitting is possible? I know I could just split them regularly and create a new row for each instance, but this would distort the truth in this image..
CodePudding user response:
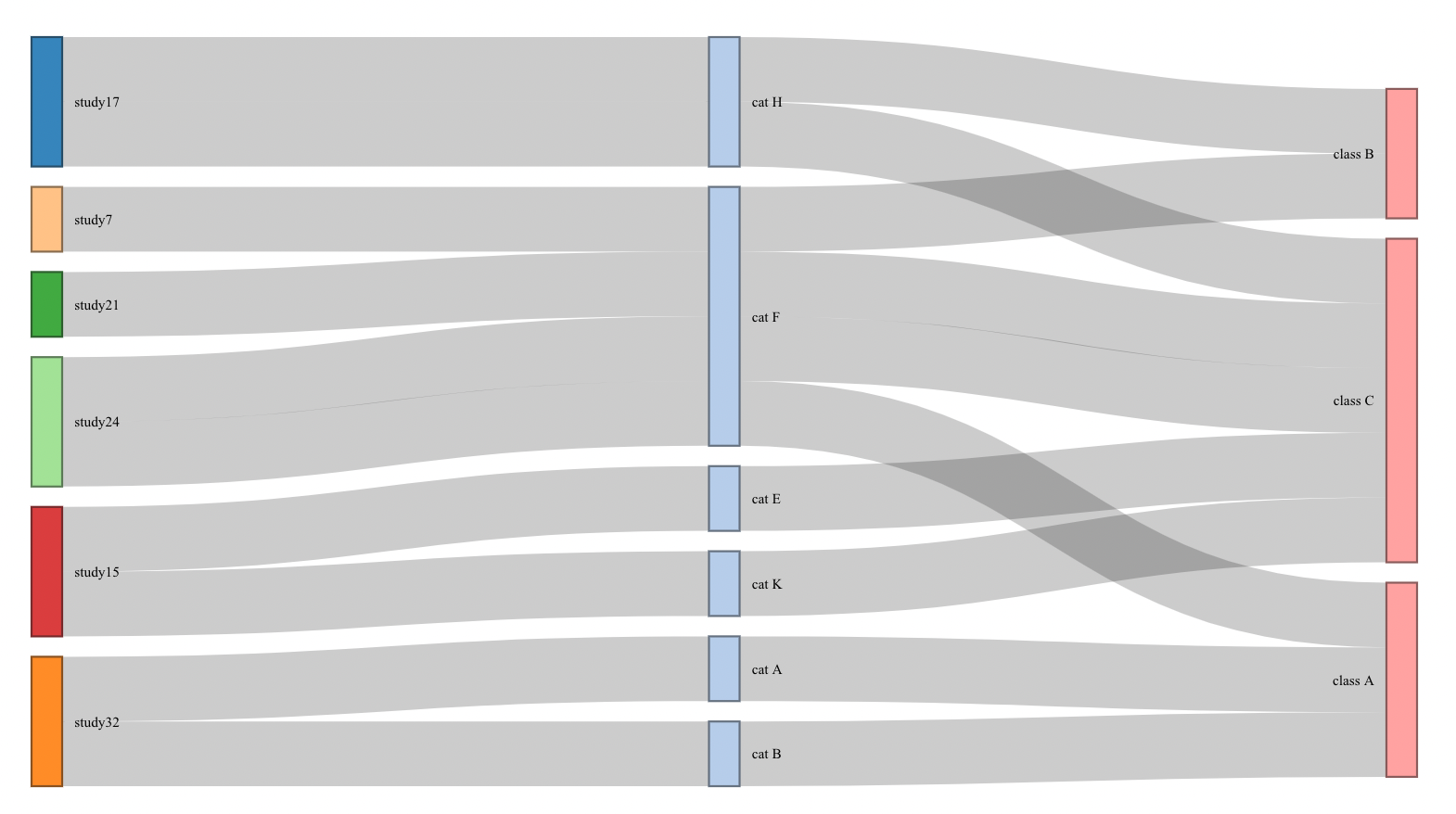
We can update the size of rectangles value based on split. This should avoid distorting the truth.
library(networkD3)
library(data.table)
setDT(d)
# make links
links <- rbind(d[, .(source = Study, target = Category) ],
d[, .(source = Category, target = Class) ])
links[, rn := .I]
# adjust value, based on "split"
links <- links[, strsplit(source, split = ";", fixed = TRUE), by = .(source, target, rn)
][, .(source = V1, target, rn)
][, strsplit(target, split = ";", fixed = TRUE), by = .(source, target, rn)
][, .(source, target = V1, rn)
][, .(source, target, value = 1/.N), by = rn]
# make nodes
nodes <- data.frame(name = unique(unlist(links[,.(source, target)])))
nodes$label <- nodes$name
# update link ids
links$source_id <- match(links$source, nodes$name) - 1
links$target_id <- match(links$target, nodes$name) - 1
# plot
sankeyNetwork(Links = links, Nodes = nodes, Source = 'source_id',
Target = 'target_id', Value = 'value', NodeID = 'label')
CodePudding user response:
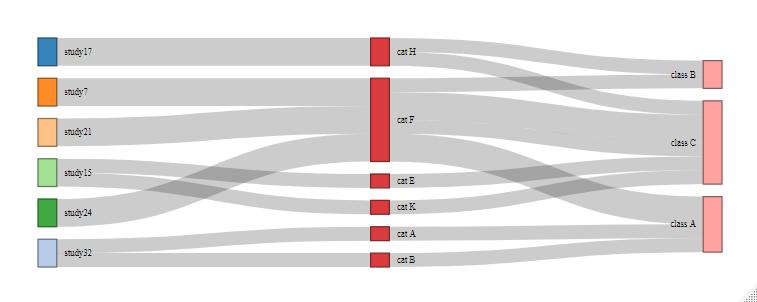
I presume this is what you have done already...
library(dplyr)
library(tidyr)
library(networkD3)
data <- tibble::tribble(
~Study, ~Category, ~Class,
"study17", "cat H", "class B;class C",
"study32", "cat A;cat B", "class A",
"study7", "cat F", "class A",
"study21", "cat F", "class C",
"study24", "cat F", "class B;class C",
"study15", "cat E;cat K", "class C"
)
links <-
data %>%
mutate(row = row_number()) %>% # add a row id
pivot_longer(-row, names_to = "column", values_to = "source") %>% # gather all columns
mutate(column = match(column, names(data))) %>% # convert col names to col ids
group_by(row) %>%
mutate(target = lead(source, order_by = column)) %>% # get target from following node in row
ungroup() %>%
filter(!is.na(target)) %>% # remove links from last column in original data
mutate(source = paste0(source, '_', column)) %>%
mutate(target = paste0(target, '_', column 1)) %>%
select(source, target)
nodes <- data.frame(name = unique(c(links$source, links$target)))
nodes$label <- sub('_[0-9]*$', '', nodes$name) # remove column id from node label
links$source_id <- match(links$source, nodes$name) - 1
links$target_id <- match(links$target, nodes$name) - 1
links$value <- 1
sankeyNetwork(Links = links, Nodes = nodes, Source = 'source_id',
Target = 'target_id', Value = 'value', NodeID = 'label')
you could reshape your original data like this
data2 <- data %>% tidyr::separate_rows(everything(), sep = ";")
data2
#> # A tibble: 10 × 3
#> Study Category Class
#> <chr> <chr> <chr>
#> 1 study17 cat H class B
#> 2 study17 cat H class C
#> 3 study32 cat A class A
#> 4 study32 cat B class A
#> 5 study7 cat F class A
#> 6 study21 cat F class C
#> 7 study24 cat F class B
#> 8 study24 cat F class C
#> 9 study15 cat E class C
#> 10 study15 cat K class C
links <-
data2 %>%
mutate(row = row_number()) %>% # add a row id
pivot_longer(-row, names_to = "column", values_to = "source") %>% # gather all columns
mutate(column = match(column, names(data2))) %>% # convert col names to col ids
group_by(row) %>%
mutate(target = lead(source, order_by = column)) %>% # get target from following node in row
ungroup() %>%
filter(!is.na(target)) %>% # remove links from last column in original data
mutate(source = paste0(source, '_', column)) %>%
mutate(target = paste0(target, '_', column 1)) %>%
select(source, target)
nodes <- data.frame(name = unique(c(links$source, links$target)))
nodes$label <- sub('_[0-9]*$', '', nodes$name) # remove column id from node label
links$source_id <- match(links$source, nodes$name) - 1
links$target_id <- match(links$target, nodes$name) - 1
links$value <- 1
sankeyNetwork(Links = links, Nodes = nodes, Source = 'source_id',
Target = 'target_id', Value = 'value', NodeID = 'label')