I'm working on a project that requires me to web scrape IMDB and builds a pd dataframe.
This is the url I am currently working on: 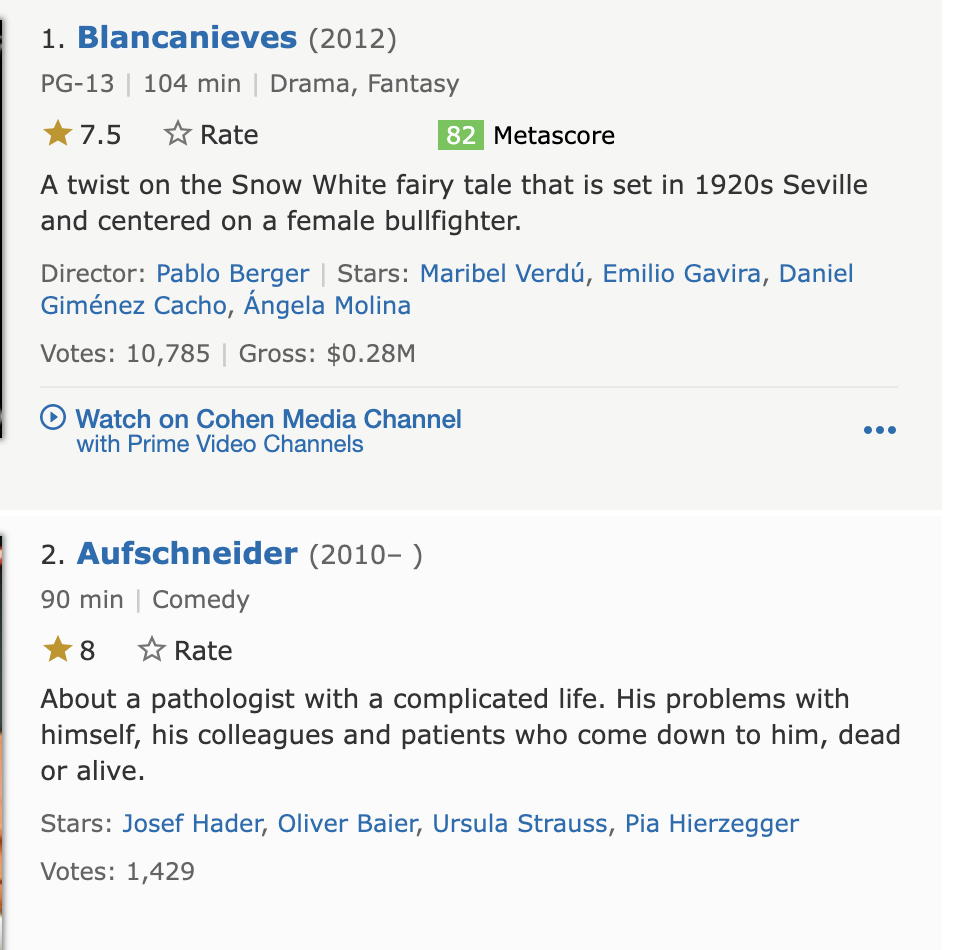
The html code looks like this:
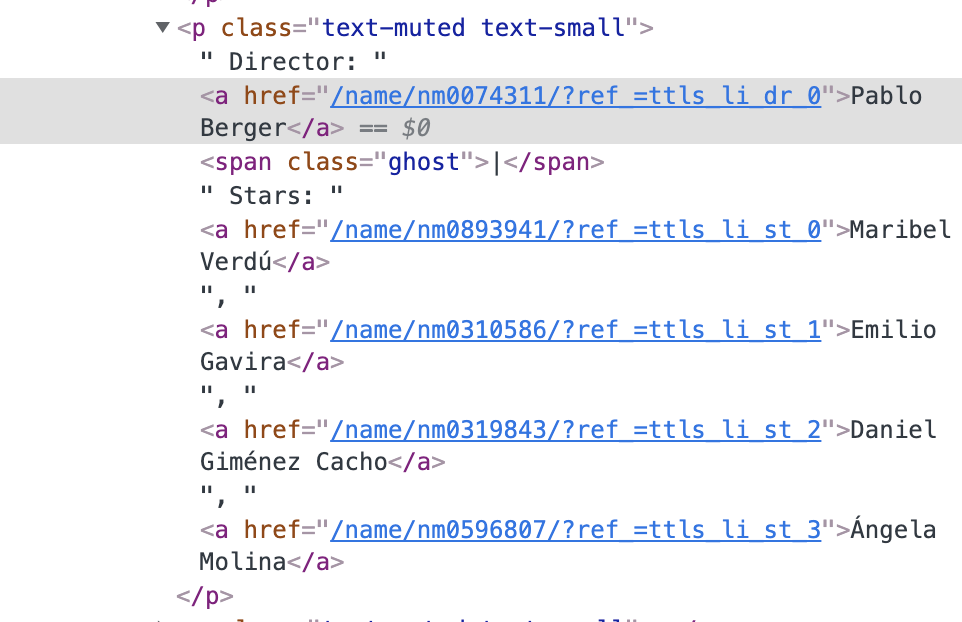
I wrote a function that uses Beautiful Soup to get each director from the html (text_muted is just the part of code on my screen shot):
def getDirector(text_muted):
try:
return text_muted.find("a").getText()
except:
return 'NA'
text_muted_stuff = movie.find_all("p", {"class": "text-muted text-small"})[1]
director = getDirector(text_muted_stuff) # Need to seperate director and actor
movie_director.append(director)
I managed to get all the directors and stars in a single list, but I want to be more specific and just fill the list with directors only (append NA if no director for any movie). I am not sure if I can achieve this with Beautiful Soup or any hard code.
Thanks
CodePudding user response:
EDIT: diggusbickus comment is mutch more strict, so you do not have to check twice - nice. Changed full example to it´s approache, result is the same.
[x.text for x in d] if (d := item.select('a[href*="_dr_"]')) else None
Attribute selectors
[href*="_dr_"] - represents elements with an attribute named href whose value containing the substring _dr_.
First approach
You can select the director with css selector and a condition that also checks the href.
[x.text for x in d if '_dr_' in x['href']] if (d := item.select('p:-soup-contains("Director:") a')) else None
Select all
<a>in a<p>that contains Director:item.select('p:-soup-contains("Director:") a')Check if element is not
Noneelse set value of director toNoneCheck if there is
_dr_in thehref, to be sure its a directorif '_dr_' in x['href']
Example (https://www.imdb.com/search/title/?genres=action)
import requests
from bs4 import BeautifulSoup
url = 'https://www.imdb.com/search/title/?genres=action'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
page = requests.get(url,headers=headers)
soup = BeautifulSoup(page.text, 'html.parser')
data = []
for item in soup.select('.lister-item'):
data.append({
'title':item.h3.a.text,
'url':'https://www.imdb.com' item.a['href'],
# if you do not like lists in your data frame, simply join ','.join([x.text for x in d])
'director': [x.text for x in d] if (d := item.select('a[href*="_dr_"]')) else None,
'stars':[x.text for x in s] if (d := item.select('a[href*="_st_"]')) else None
})
pd.DataFrame(data)
Output
| title | url | director | stars |
|---|---|---|---|
| Das Rad der Zeit | https://www.imdb.com/title/tt7462410/?ref_=adv_li_i | ['Rosamund Pike', 'Daniel Henney', 'Madeleine Madden', 'Zoë Robins'] | |
| Arcane | https://www.imdb.com/title/tt11126994/?ref_=adv_li_i | ['Kevin Alejandro', 'Jason Spisak', 'Hailee Steinfeld', 'Harry Lloyd'] | |
| Hawkeye | https://www.imdb.com/title/tt10160804/?ref_=adv_li_i | ['Jeremy Renner', 'Hailee Steinfeld', 'Florence Pugh', 'Tony Dalton'] | |
| Cowboy Bebop | https://www.imdb.com/title/tt1267295/?ref_=adv_li_i | ['John Cho', 'Mustafa Shakir', 'Daniella Pineda', 'Elena Satine'] | |
| Red Notice | https://www.imdb.com/title/tt7991608/?ref_=adv_li_i | ['Rawson Marshall Thurber'] | ['Dwayne Johnson', 'Ryan Reynolds', 'Gal Gadot', 'Ritu Arya'] |
| Spider-Man: No Way Home | https://www.imdb.com/title/tt10872600/?ref_=adv_li_i | ['Jon Watts'] | ['Zendaya', 'Benedict Cumberbatch', 'Tom Holland', 'Marisa Tomei'] |
| Dune | https://www.imdb.com/title/tt1160419/?ref_=adv_li_i | ['Denis Villeneuve'] | ['Timothée Chalamet', 'Rebecca Ferguson', 'Zendaya', 'Oscar Isaac'] |
| Shang-Chi and the Legend of the Ten Rings | https://www.imdb.com/title/tt9376612/?ref_=adv_li_i | ['Destin Daniel Cretton'] | ['Simu Liu', 'Awkwafina', 'Tony Chiu-Wai Leung', 'Ben Kingsley'] |
| James Bond 007: Keine Zeit zu sterben | https://www.imdb.com/title/tt2382320/?ref_=adv_li_i | ['Cary Joji Fukunaga'] | ['Daniel Craig', 'Ana de Armas', 'Rami Malek', 'Léa Seydoux'] |
| Eternals | https://www.imdb.com/title/tt9032400/?ref_=adv_li_i | ['Chloé Zhao'] | ['Gemma Chan', 'Richard Madden', 'Angelina Jolie', 'Salma Hayek'] |
| Venom: Let There Be Carnage | https://www.imdb.com/title/tt7097896/?ref_=adv_li_i | ['Andy Serkis'] | ['Tom Hardy', 'Woody Harrelson', 'Michelle Williams', 'Naomie Harris'] |
CodePudding user response:
The easiest way I can see to separate directors and stars whilst remaining in bs4, even if there is no director listed, is to use the href differences between them.
The href tag for the director contains "dr_0", which is probably the same for all titles (should check this), movies with multiple directors will probably follow the same pattern as the stars, and advance in such as "dr_1", "dr_2", ...
So to get only directors and only stars from the html source, you can use:
import re
# could do with a copy of the html source to test this,
# please provide a test html string of the element if this doesn't work first time
def get_directors(text_muted) -> list:
# find all 'a' tags in that small element, if the href contains "dr_%d" then include the name in the returned list. return empty list if no directors.
names = text_muted.find_all("a")
return [element.string for element in names if re.search("dr_[0-9]", element.get("href", ""))]
def get_stars(text_muted) -> list:
# find all 'a' tags in that small element, if the href contains "st_%d" then include the name in the returned list. return empty list if no stars.
names = text_muted.find_all("a")
return [element.string for element in names if re.search("st_[0-9]", element.get("href", ""))]
This should be safe enough, but if the hrefs aren't as predictably as they look, then you could dump the element string and split that on the patterns "Director:" and "Stars:".
Btw, I tend to use manual string searches/regex when html-scraping as for the cost of just a little more effort getting the tags split correctly the speed improvement over bs4 is around 100-200x, so that's worth considering.