I'm trying to add a column of fake data into a dataframe. It doesn't not matter what the contents of the dataframe are. I just want to add a column of randomly generated fake data, e.g., randomly generated first names with one name per line. Here is some dummy data to play with but I repeat, the contents of the dataframe do not matter:
from faker import Faker
faker = Faker("en_GB")
contact = [faker.profile() for i in range(0, 100)]
contact = spark.createDataFrame(contact)
I'm trying to create a class with functions to do this for different columns as so:
class anonymise:
@staticmethod
def FstName():
def FstName_values():
faker = Faker("en_GB")
return faker.first_name()
FstName_udf = udf(FstName_values, StringType())
return FstName_udf()
The class above has one function as an example but the actual class has multiple functions of exactly the same template, just for different columns, e.g., LastName.
Then, I'm adding in the new columns as so:
contact = contact \
.withColumn("FstName", anonymise.FstName())
I'm using this process to replace real data with realistic-looking, fake, randomly generated data.
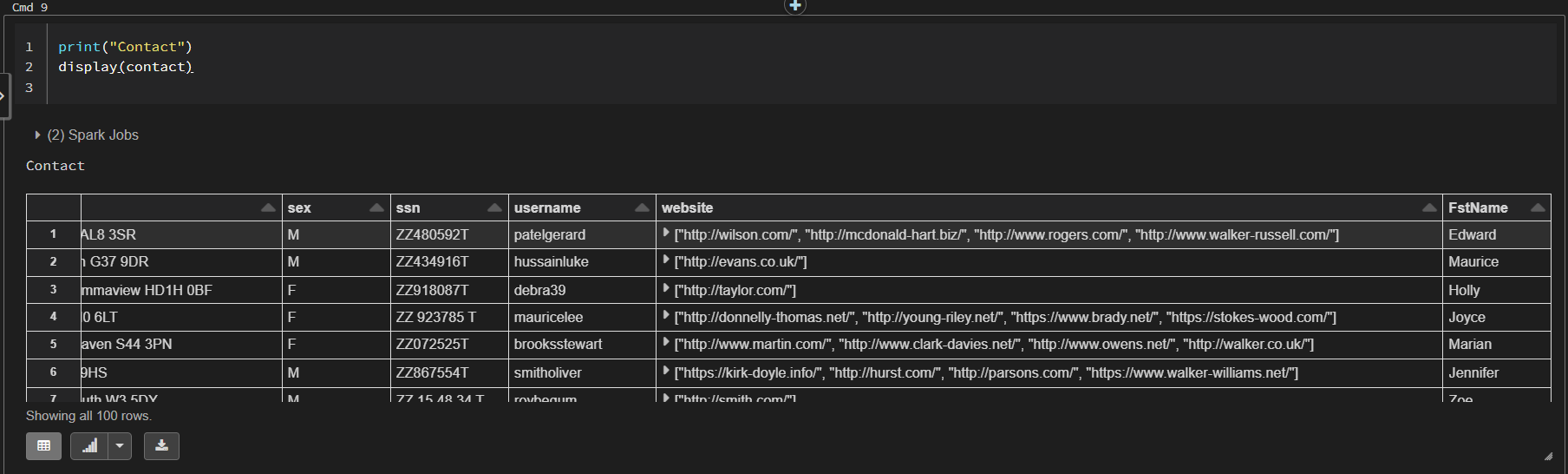
This appears to works fine and runs quickly. However, I noticed that every time I display the new dataframe, it will try to generate an entirely new column:
First try:
Second try immediately after the first:
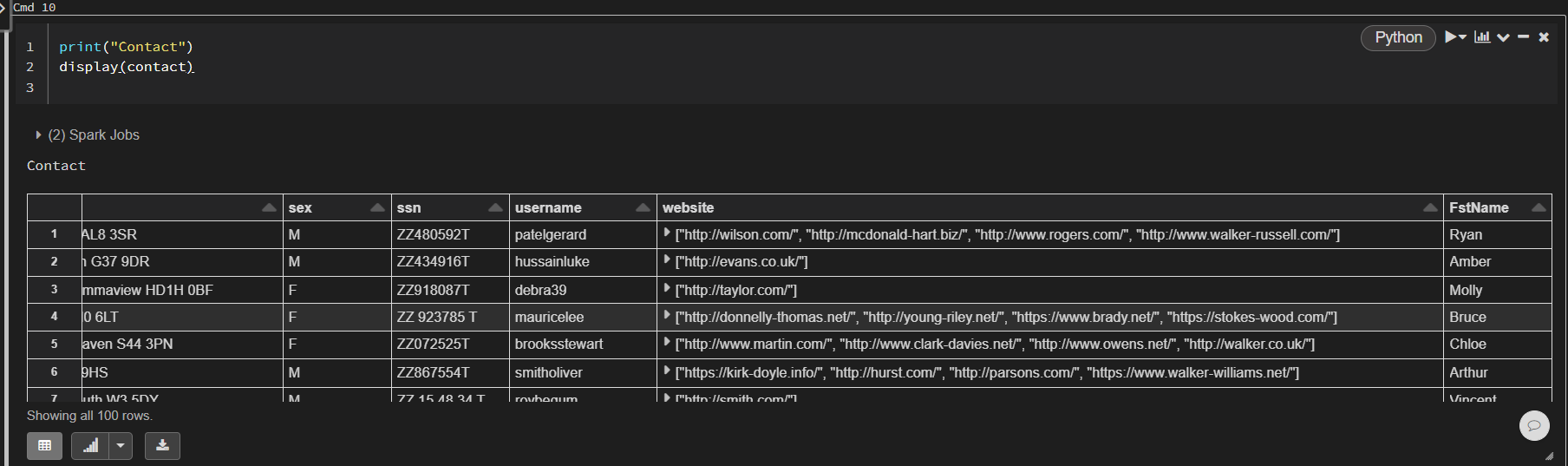
This means that the dataframe isn't just one static dataframe with data and it will try to generate a new column for every subsequent command. This is causing me issues further down the line when I try to write the data to an external file.
I would just like it to generate the column once with some static data that is easily callable. I don't even want it to regenerate the same data. The generation process should happen once.
I've tried copying to a pandas dataframe but the dataframe is too large for this to work (1.3 million rows) and I can't seem to write a smaller version to an external file anyway.
Any help on this issue appreciated!
Many thanks,
Carolina
CodePudding user response:
Since you are using spark, it is doing the computation across multiple nodes. What you can try is add a contact.persist() after doing the anonymization.
You can read more about persist HERE.
CodePudding user response:
So it was a pretty simple fix in the end...
By putting faker = Faker("en_GB") inside the function where it was, I was generating an instance of faker for every row. I simply had to remove it from within the function and generate the instance outside the class. So now, although it does generate the data every time a command is called, it does so very quickly even for large dataframes and I haven't run into any issues for any subsequent commands.