There's a table containing a list of 3 employees and 3-4 courses they are supposed to take respectively. I want to create individual PDFs for every employee in this table. First PDF will have list of 3 courses to be taken by Emp1, 2nd PDF will have list of 3 courses to be taken by Emp2 and so on.
The below code is creating just 1 PDF and contains list of all courses for all employees together.
My idea is to initially split/ group the data based on EmpNo and then create individual PDF and to do this I need to create a For Loop for iterating. However, I am unable to figure this...
DataFrame Code
pip install fpdf #To generate PDF
import pandas as pd
data = {'EmpNo': ['123','123','123','456','456', '456','456','789','789','789'],
'First Name': ['John', 'John', 'John', 'Jane', 'Jane', 'Jane', 'Jane', 'Danny', 'Danny', 'Danny'],
'Last Name': ['Doe', 'Doe' ,'Doe', 'Doe' ,'Doe', 'Doe', 'Doe', 'Roberts', 'Roberts', 'Roberts'],
'Activity Code': ['HR-CONF-1', 'HR-Field-NH-ONB','COEATT-2021','HR-HBK-CA-1','HR-WD-EMP','HR-LIST-1','HS-Guide-3','HR-WD-EMP','HR-LIST-1','HS-Guide-3'],
'RegistrationDate': ['11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021','11/22/2021', '11/22/2021', '11/22/2021','11/22/2021']}
df = pd.DataFrame(data = data, columns = ['EmpNo','First Name', 'Last Name', 'Activity Code', 'RegistrationDate'])
employees = data['EmpNo']
employees = data.drop_duplicates(subset=['EmpNo'])
print(df)
Input looks like this,
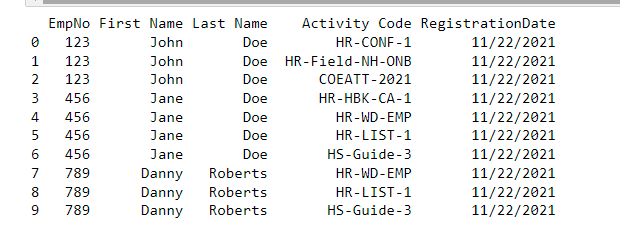
PDF Generation Code
from fpdf import FPDF
class PDF(FPDF):
def header(self):
# Arial bold 15
self.set_font('Helvetica', 'B', 15)
# Move to the right
self.cell(80)
# Title
self.cell(42, 2, 'Plan', 0, 0, 'C')
# Line break
self.ln(20)
# Page footer
def footer(self):
# Position at 1.5 cm from bottom
self.set_y(-15)
# Arial italic 8
self.set_font('Helvetica', 'I', 8)
# Page number
self.cell(0, 10, 'Page ' str(self.page_no()) '/{nb}', 0, 0, 'C')
# Footer image First is horizontal, second is vertical, third is size
for EmpNo in employees['EmpNo']:
print (EmpNo)
# Instantiation of inherited class
pdf = PDF()
pdf.alias_nb_pages()
pdf.add_page()
pdf.set_font('Helvetica', '', 11)
pdf.cell(80, 6, 'Employee ID: ' str(data.loc[0]['EmpNo']), 0, 1, 'L')
pdf.ln(2.5)
pdf.multi_cell(160, 5, 'Dear ' str(data.loc[0]['First Name']) ' ' str(data.loc[0]['Last Name']) ', Please find below your Plan.', 0, 1, 'L')
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.set_font('Helvetica', 'B', 13)
pdf.cell(80, 6, 'Name', 0, 0, 'L')
pdf.cell(40, 6, 'Date', 0, 0, 'L')
pdf.cell(40, 6, 'Link', 0, 1, 'L')
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.set_font('Helvetica', '', 8)
for i in range (len(data)):
pdf.set_font('Helvetica', '', 8)
pdf.cell(80, 6, data.loc[0 i]['Activity Code'], 0, 0, 'L')
#pdf.cell(40, 6, data.loc[0 i]['Activity Link'], 0, 1, 'L')
pdf.cell(40, 6, data.loc[0 i]['RegistrationDate'], 0, 0, 'L')
pdf.set_font('Helvetica', 'U', 8)
pdf.cell(40, 6, 'Click Here', 0, 1, 'L', link = 'www.google.com')
pdf.set_font('Helvetica', 'B', 10)
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.cell(80, 6, 'IF YOU REQUIRE ANY HELP, PLEASE CONTACT US', 0, 0, 'L')
pdf.output(str(data.loc[0]['First Name']) ' ' str(data.loc[0]['Last Name']) '.pdf', 'F')
Here's a snap of PDF generated.
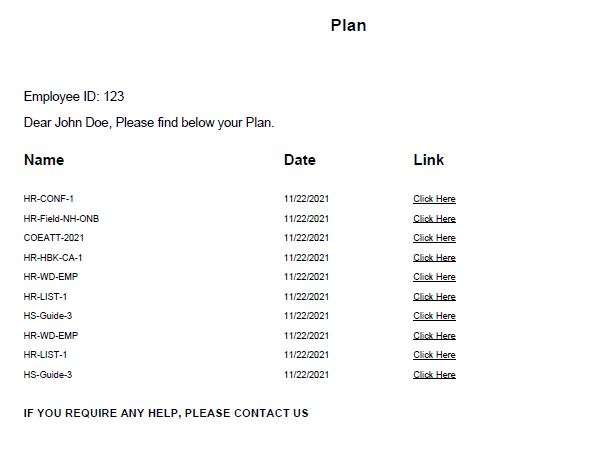
I can split the data using below code, but I am stuck at how to call out individual splits and then further create multiple PDF
splits = list(data.groupby('EmpNo'))
Any help would be greatly appreciated. Thanks.
CodePudding user response:
I would write the groupby like this:
for EmpNo, data in df.groupby("EmpNo"):
For each group, the groupby will return the variable it groups on, and the dataframe which matches that variable.
Next, I would extract the first row of that dataframe. This is to make it easier to get the name and similar attributes.
first_row = data.iloc[0]
(What's the difference between iloc and loc?)
Since we have the employee ID already, we can skip looking it up in the dataframe. For other attributes, we can look it up like first_row['First Name'].
pdf.cell(80, 6, 'Employee ID: ' str(EmpNo), 0, 1, 'L')
# ...
pdf.multi_cell(160, 5, 'Dear ' str(first_row['First Name']) ' ' str(first_row['Last Name']) ', Please find below your Plan.', 0, 1, 'L')
Next, in this loop which loops over the subset, I would use .iterrows() to do the loop instead of using range() and .loc. This is easier and won't break if the index of your dataframe doesn't start with zero. (After grouping, the second group's index won't start with zero anymore.)
Here is the final source code after the changes:
import pandas as pd
data = {'EmpNo': ['123','123','123','456','456', '456','456','789','789','789'],
'First Name': ['John', 'John', 'John', 'Jane', 'Jane', 'Jane', 'Jane', 'Danny', 'Danny', 'Danny'],
'Last Name': ['Doe', 'Doe' ,'Doe', 'Doe' ,'Doe', 'Doe', 'Doe', 'Roberts', 'Roberts', 'Roberts'],
'Activity Code': ['HR-CONF-1', 'HR-Field-NH-ONB','COEATT-2021','HR-HBK-CA-1','HR-WD-EMP','HR-LIST-1','HS-Guide-3','HR-WD-EMP','HR-LIST-1','HS-Guide-3'],
'RegistrationDate': ['11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021','11/22/2021', '11/22/2021', '11/22/2021','11/22/2021']}
df = pd.DataFrame(data = data, columns = ['EmpNo','First Name', 'Last Name', 'Activity Code', 'RegistrationDate'])
from fpdf import FPDF
class PDF(FPDF):
def header(self):
# Arial bold 15
self.set_font('Helvetica', 'B', 15)
# Move to the right
self.cell(80)
# Title
self.cell(42, 2, 'Plan', 0, 0, 'C')
# Line break
self.ln(20)
# Page footer
def footer(self):
# Position at 1.5 cm from bottom
self.set_y(-15)
# Arial italic 8
self.set_font('Helvetica', 'I', 8)
# Page number
self.cell(0, 10, 'Page ' str(self.page_no()) '/{nb}', 0, 0, 'C')
# Footer image First is horizontal, second is vertical, third is size
for EmpNo, data in df.groupby("EmpNo"):
# Get first row of grouped dataframe
first_row = data.iloc[0]
# Instantiation of inherited class
pdf = PDF()
pdf.alias_nb_pages()
pdf.add_page()
pdf.set_font('Helvetica', '', 11)
pdf.cell(80, 6, 'Employee ID: ' str(EmpNo), 0, 1, 'L')
pdf.ln(2.5)
pdf.multi_cell(160, 5, 'Dear ' str(first_row['First Name']) ' ' str(first_row['Last Name']) ', Please find below your Plan.', 0, 1, 'L')
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.set_font('Helvetica', 'B', 13)
pdf.cell(80, 6, 'Name', 0, 0, 'L')
pdf.cell(40, 6, 'Date', 0, 0, 'L')
pdf.cell(40, 6, 'Link', 0, 1, 'L')
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.set_font('Helvetica', '', 8)
for _, row in data.iterrows():
pdf.set_font('Helvetica', '', 8)
pdf.cell(80, 6, row['Activity Code'], 0, 0, 'L')
#pdf.cell(40, 6, row['Activity Link'], 0, 1, 'L')
pdf.cell(40, 6, row['RegistrationDate'], 0, 0, 'L')
pdf.set_font('Helvetica', 'U', 8)
pdf.cell(40, 6, 'Click Here', 0, 1, 'L', link = 'www.google.com')
pdf.set_font('Helvetica', 'B', 10)
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.cell(80, 6, 'IF YOU REQUIRE ANY HELP, PLEASE CONTACT US', 0, 0, 'L')
pdf.output(str(first_row['First Name']) ' ' str(first_row['Last Name']) '.pdf', 'F')
Tested, and it works.