# -*- coding: utf-8 -*-
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--ignore-certificate-errors')
options.add_argument('--ignore-ssl-errors')
PATH='C:\\Users\\admin\\Documents\\chromedriver.exe'
driver = webdriver.Chrome(PATH,chrome_options=options)
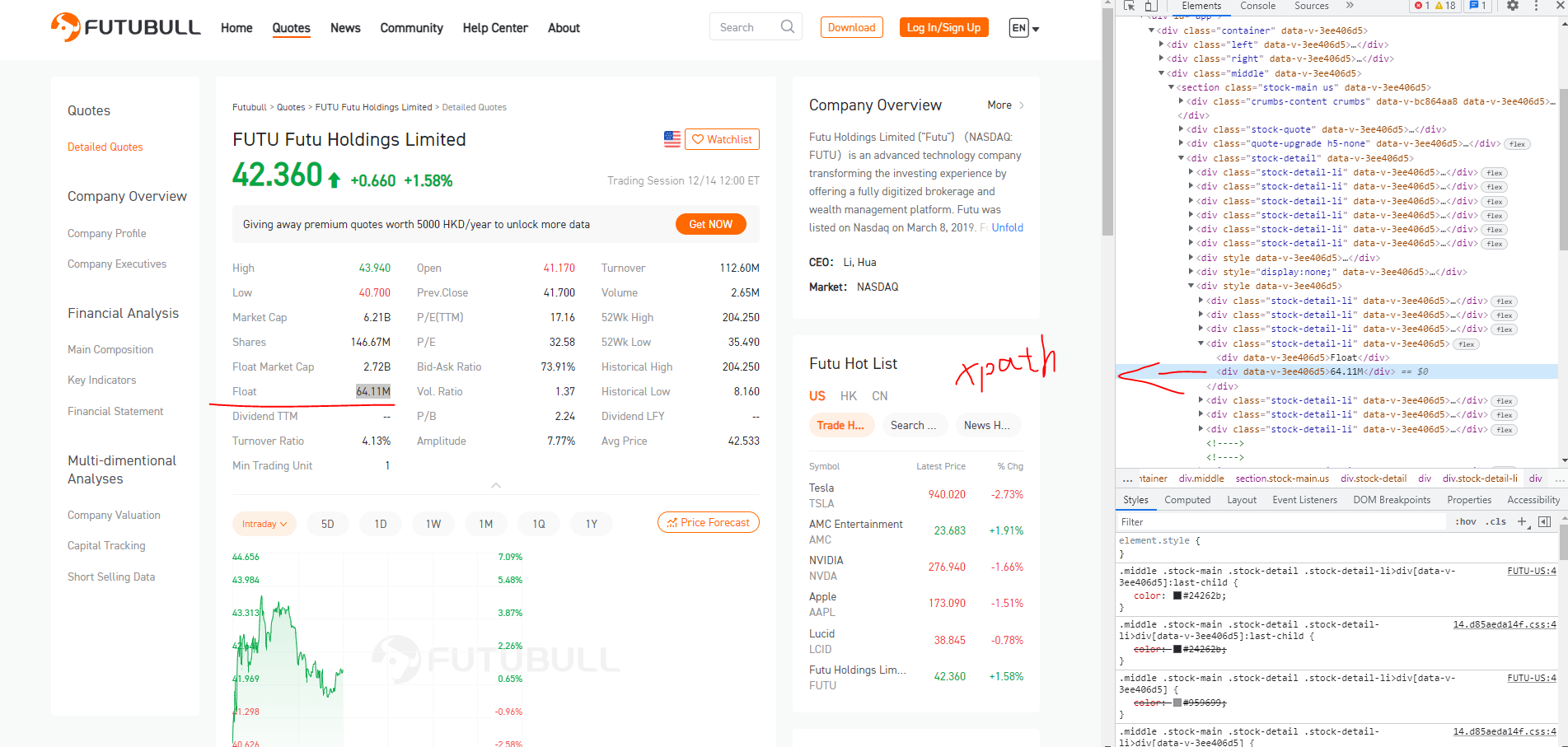
driver.get('https://www.futunn.com/en/stock/FUTU-US')
freeflowtickers=driver.find_element_by_xpath("//*[@id=\"app\"]/div/div[3]/section[1]/div[4]/div[9]/div[4]/div[2]")
print(freeflowtickers)
print(freeflowtickers.text)
Then run it, in the console, you get
<selenium.webdriver.remote.webelement.WebElement (session="08bc2133e5e3b6911cea32c6750833a8", element="e38cb418-2e37-428d-af4b-e01dd3e691ae")>
But after it no text is aquired.
How could this happen?
CodePudding user response:
So this isn't the cleanest solution but I just tested it and it's working.
float_element = driver.find_element_by_xpath('//*[@id="app"]/div/div[3]/section[1]/div[4]/div[9]/div[4]')
number = float_element.text.split("\n")[1]
I've grabbed the xpath of the parent div tag which contains two lines of text "Float" and the number which are separated by a newline.
CodePudding user response:
To print the text 64.11M you can use either of the following Locator Strategies:
Using xpath and
get_attribute("innerHTML"):print(driver.find_element(By.XPATH, "//div[text()='Float']//following-sibling::div[1]").get_attribute("innerHTML"))Using xpath and text attribute:
print(driver.find_element(By.XPATH, "//div[text()='Float']//following-sibling::div[1]").text)
Ideally you need to induce WebDriverWait for the visibility_of_element_located() and you can use either of the following Locator Strategies:
Using XPATH and text attribute:
driver.get("https://www.futunn.com/en/stock/FUTU-US") WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//div[@class='stock-detail-btn']/i"))).click() print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[text()='Float']//following-sibling::div[1]"))).text)Using XPATH and
get_attribute("innerHTML"):driver.get("https://www.futunn.com/en/stock/FUTU-US") WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//div[@class='stock-detail-btn']/i"))).click() print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[text()='Float']//following-sibling::div[1]"))).get_attribute("innerHTML"))Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC
You can find a relevant discussion in How to retrieve the text of a WebElement using Selenium - Python
References
Link to useful documentation:
get_attribute()methodGets the given attribute or property of the element.textattribute returnsThe text of the element.- Difference between text and innerHTML using Selenium