I am currently working on a dataset which has information on total sales for each product id and product sub category. For eg, let us consider that there are three products 1, 2 and 3. There are three product sub categories - A,B,C, one or two or all of which may comprise the products 1, 2 and 3. For instance, I have included a sample table below:
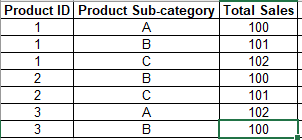
Now, I would like to add a flag column 'Flag' which can assign 1 or 0 to each product id depending on whether that product id is contains record of product sub category 'C'. If it does contain 'C', then assign 1 to the flag column. Otherwise, assign 0. Below is the desired output.
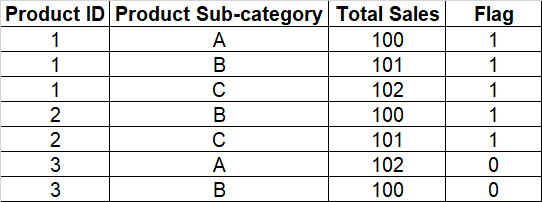
I am currently not able to do this in pandas. Could you help me out? Thank you so much!
CodePudding user response:
use pandas transform and contains. transform applies the lambda function to all rows in the dataframe.
txt="""ID,Sub-category,Sales
1,A,100
1,B,101
1,C,102
2,B,100
2,C,101
3,A,102
3,B,100"""
df = pd.read_table(StringIO(txt), sep=',')
#print(df)
list_id=list(df[df['Sub-category'].str.contains('C')]['ID'])
df['flag']=df['ID'].apply(lambda x: 1 if x in list_id else 0 )
print(df)
output:
ID Sub-category Sales flag
0 1 A 100 1
1 1 B 101 1
2 1 C 102 1
3 2 B 100 1
4 2 C 101 1
5 3 A 102 0
6 3 B 100 0
CodePudding user response:
Try this:
Flag = [ ]
for i in dataFrame["Product sub-category]:
if i == "C":
Flag.append(1)
else:
Flag.append(0)
So you have a list called "Flag" and can add it to your dataframe.
CodePudding user response:
You can add a temporary column, isC to check for your condition. Then check for the number of isC's inside every "Product Id" group (with .groupby(...).transform).
check = (
df.assign(isC=lambda df: df["Product Sub-category"] == "C")
.groupby("Product Id").isC.transform("sum")
)
df["Flag"] = (check > 0).astype(int)