I have two columns in a dataframe named [Timeline and Start] and their type is a timestamp.
I want to write a function that can set a threshold value = 30 seconds, and if the time in the start column is close to any value in the time of the Timeline column by the threshold value, this value from the start column will be moved under the Timeline column.
For example, insert 00:58:26 under 00:11:27 in the same start column if they have the difference in time of the threshold value.
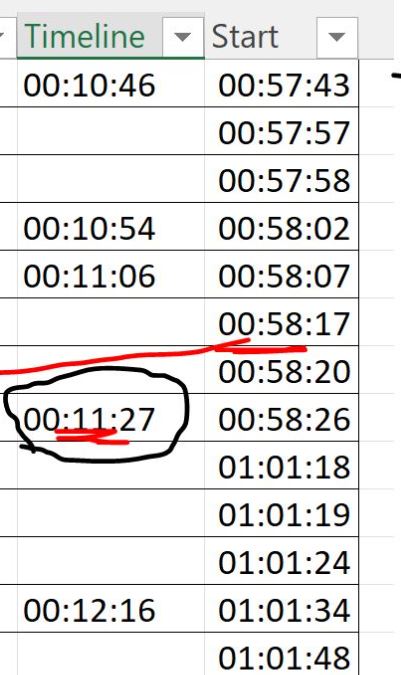
My code which I tried can only find time similarities as objects, which is not the required task.
threshold = 0.8
from difflib import SequenceMatcher
def similar(a, b):
return SequenceMatcher(None, a, b).ratio()
result_1 = pd.DataFrame(columns = ["Timeline", "Start"])
for i, r1 in df1.iterrows():
for j, r2 in df2.iterrows():
if similar(r1["Timeline"], r2["Start"]) > threshold:
result_1.loc[len(result_1.index)] = [r1["Timeline"], r2["Start"]]
print(result_1)
CodePudding user response:
Your question is not very clear. If you simply want to replace all values in Timeline with the value in Start as soon as the difference is less than a threshold, then here is the code:
import pandas as pd
# Our DataFrame
df = pd.DataFrame(
index=list(range(13)),
columns=["Timeline", "Start"]
)
# Raw data (HH:MM:ss)
df["Start"] = [
"00:57:43",
"00:57:57",
"00:57:58",
"00:58:02",
"00:58:07",
"00:58:17",
"00:58:20",
"00:58:26",
"01:01:18",
"01:01:19",
"01:01:24",
"01:01:34",
"01:01:48"
]
# Put the rest of the data into the DataFrame
df.loc[[0, 3, 4, 7, 11], "Timeline"] = [
"00:10:46",
"00:10:54",
"00:11:06",
"00:11:27",
"00:12:16"
]
# Converting to timestamps
for col in df.columns:
df[col] = pd.to_datetime(df[col])
# Difference
df["absdiff"] = pd.DataFrame.abs(
(df["Timeline"] - df["Start"]).astype("timedelta64[s]"))
# Threshold in seconds
threshold_in_seconds = 2828
# Replace
idx = df[df["absdiff"] < threshold_in_seconds]["Timeline"].index
df.loc[idx, "Timeline"] = df.loc[idx, "Start"]
which turns
Timeline Start absdiff
0 2021-12-19 00:10:46 2021-12-19 00:57:43 2817.0
1 NaT 2021-12-19 00:57:57 NaN
2 NaT 2021-12-19 00:57:58 NaN
3 2021-12-19 00:10:54 2021-12-19 00:58:02 2828.0
4 2021-12-19 00:11:06 2021-12-19 00:58:07 2821.0
5 NaT 2021-12-19 00:58:17 NaN
6 NaT 2021-12-19 00:58:20 NaN
7 2021-12-19 00:11:27 2021-12-19 00:58:26 2819.0
8 NaT 2021-12-19 01:01:18 NaN
9 NaT 2021-12-19 01:01:19 NaN
10 NaT 2021-12-19 01:01:24 NaN
11 2021-12-19 00:12:16 2021-12-19 01:01:34 2958.0
12 NaT 2021-12-19 01:01:48 NaN
into this
Timeline Start absdiff
0 2021-12-19 00:57:43 2021-12-19 00:57:43 2817.0
1 NaT 2021-12-19 00:57:57 NaN
2 NaT 2021-12-19 00:57:58 NaN
3 2021-12-19 00:10:54 2021-12-19 00:58:02 2828.0
4 2021-12-19 00:58:07 2021-12-19 00:58:07 2821.0
5 NaT 2021-12-19 00:58:17 NaN
6 NaT 2021-12-19 00:58:20 NaN
7 2021-12-19 00:58:26 2021-12-19 00:58:26 2819.0
8 NaT 2021-12-19 01:01:18 NaN
9 NaT 2021-12-19 01:01:19 NaN
10 NaT 2021-12-19 01:01:24 NaN
11 2021-12-19 00:12:16 2021-12-19 01:01:34 2958.0
12 NaT 2021-12-19 01:01:48 NaN
If you dont like the absdiff column then just add
df.drop(labels=["absdiff"], axis="columns", inplace=True)
to your script.
CodePudding user response:
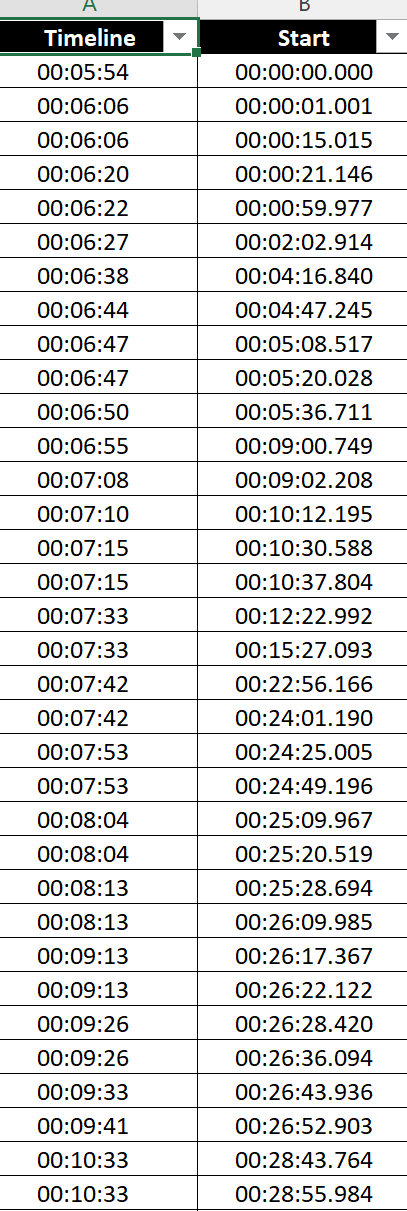
The Timeline column is the actual time, while the start column is just a predicted one. I want to move every value from the start column to be below the Timeline column if they have a difference in time of 30 seconds.