Background
I've got a dataset d:
d <- data.frame(ID = c("a","a","b","b", "c","c"),
event = c(0,1,0,0,1,1),
event_date = as.Date(c("2011-01-01","2012-08-21","2011-12-23","2011-12-31","2013-03-14","2015-07-12")),
entry_date = as.Date(c("2009-01-01","2009-01-01","2011-09-12","2011-09-12","2005-03-01","2005-03-01")),
stringsAsFactors=FALSE)
It looks like this:
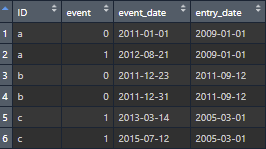
As you can see, it's got 3 ID's in it, an indicator of whether they had the event, a date for that event, and a date for when they entered the dataset.
The Problem
I'd like to do some sampling of ID's in the dataset. Specifically, I'd like to sample all the rows of any distinct ID who meet the following two conditions:
- Has any
event=1 - The date of their first (chronologically earliest)
event_daterow is greater than 365 days but less than 1095 days (3 years) from theirentry_date.
Desired result
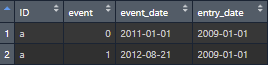
If you look at each of the 3 ID's, you'll see that only ID= a meets both of these criteria: this person has an event=1 in their second event record, and the date of their first event record is between 1 and 3 years from their entry_date (2011-01-01 is exactly two years from their entry date).
So, I'd like a dataframe that looks like this:
What I've tried
I'm halfway there: I've managed to get the code to meet my first criterion, but not the second. Have a look:
d_esired <- subset(d, ID %in% sample(unique(ID[event == 1]), 1))
How can I add the second condition?
CodePudding user response:
Using data.table we can identify those IDs, then subset
library(data.table)
setDT(d)
d[ID %in%
(d[, any(event==1 & any(event_date>(365 entry_date) & event_date<(1095 entry_date))), by=ID][V1==TRUE, ID])]
The any(event_date>(365 entry_date) tests for valid dates in any row (event can be 0 or 1), and any(event==1 & ...) tests whether that occurred and whether an event occurred at any point. That is used to return a vector of ID values. The %in% operator then tests whether IDs in d are in that vector.