I have a dataframe where some of rows having duplicated ids but different timestamp and some of rows having duplicated ids but the same timestamp but having one of following (yob and gender) columns null. Now I want to do an operation using groupby:
- if the same
idhaving differencetimestamp, want to pickup the recent timestamp. - If the same
idshaving sametimestampbut the any of column having null(yobandgender), that time, want to merge the bothidas single record without null. below I have pasted the data frame and desired output.
Input data
from pyspark.sql.functions import col, max as max_
df = sc.parallelize([
("e5882", "null", "M", "AD", "9/14/2021 13:50"),
("e5882", "null", "M", "AD", "10/22/2021 13:10"),
("5cddf", "null", "M", "ED", "9/9/2021 12:00"),
("5cddf", "2010", "null", "ED", "9/9/2021 12:00"),
("c3882", "null", "M", "BD", "11/27/2021 5:00"),
("c3882", "1975", "null", "BD", "11/27/2021 5:00"),
("9297d","1999", "null", "GF","10/18/2021 7:00"),
("9298e","1990","null","GF","10/18/2021 7:00")
]).toDF(["ID", "yob", "gender","country","timestamp"])
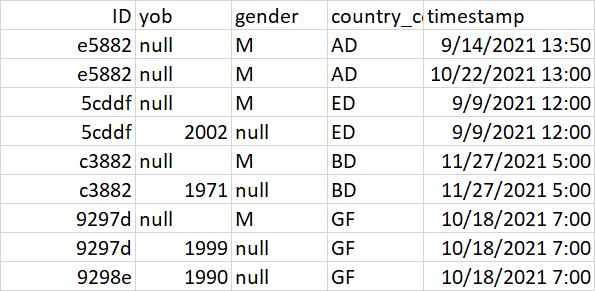
Desire output:
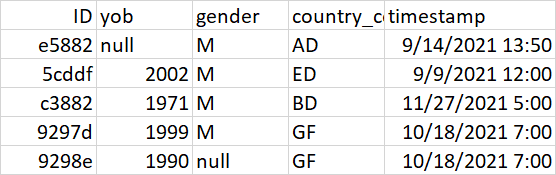
code used in this problem, but not get the accurate result, some of ids are missing,
w = Window.partitionBy('Id')
# to obtain the recent date
df1 = df.withColumn('maxB', F.max('timestamp').over(w)).where(F.col('timestamp') == F.col('maxB')).drop('maxB')
# to merge the null column based of id
(df1.groupBy('Id').agg(*[F.first(x,ignorenulls=True) for x in df1.columns if x!='Id'])).show()
CodePudding user response:
Using this input dataframe:
df = spark.createDataFrame([
("e5882", None, "M", "AD", "9/14/2021 13:50"),
("e5882", None, "M", "AD", "10/22/2021 13:10"),
("5cddf", None, "M", "ED", "9/9/2021 12:00"),
("5cddf", "2010", None, "ED", "9/9/2021 12:00"),
("c3882", None, "M", "BD", "11/27/2021 5:00"),
("c3882", "1975", None, "BD", "11/27/2021 5:00"),
("9297d", None, "M", "GF", "10/18/2021 7:00"),
("9297d", "1999", None, "GF", "10/18/2021 7:00"),
("9298e", "1990", None, "GF", "10/18/2021 7:00"),
], ["id", "yob", "gender", "country", "timestamp"])
- If the same
idhaving differencetimestamp, want to pickup the recent timestamp.
Use window ranking function to get most recent row per id. As you want to merge those with the same timestamp you can use dense_rank instead of row_number. But first you need to convert timestamp strings into TimestampType otherwise comparison won't be correct (as '9/9/2021 12:00' > '10/18/2021 7:00')
from pyspark.sql import Window
import pyspark.sql.functions as F
df_most_recent = df.withColumn(
"timestamp",
F.to_timestamp("timestamp", "M/d/yyyy H:mm")
).withColumn(
"rn",
F.dense_rank().over(Window.partitionBy("id").orderBy(F.desc("timestamp")))
).filter("rn = 1")
- If the same ids having same
timestampbut the any of column having null(yobandgender), that time, want to merge the bothidas single record without null. below I have pasted the data frame and desired output.
Now the above df_most_recent contains one or more rows having the same most recent timestamp per id, you can group by id to merge the values of the other columns like this:
result = df_most_recent.groupBy("id").agg(
*[F.collect_set(c)[0].alias(c) for c in df.columns if c!='id']
# or *[F.first(c).alias(c) for c in df.columns if c!='id']
)
result.show()
# ----- ---- ------ ------- -------------------
#|id |yob |gender|country|timestamp |
# ----- ---- ------ ------- -------------------
#|5cddf|2010|M |ED |2021-09-09 12:00:00|
#|9297d|1999|M |GF |2021-10-18 07:00:00|
#|9298e|1990|null |GF |2021-10-18 07:00:00|
#|c3882|1975|M |BD |2021-11-27 05:00:00|
#|e5882|null|M |AD |2021-10-22 13:10:00|
# ----- ---- ------ ------- -------------------