I am trying to automize plotting Likert scales from a large survey. I used the questions before as colnames, but this was not very handy, so I started to use codes and save the questions with the code in another data frame. But now I do not know how to integrate the questions in my Plots.
library(likert)
# Here comes the example data
data <- structure(list(einstieg1_1 = structure(c(5L, 5L, 5L, 4L, 5L,
5L, 5L, 5L, 5L, 5L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor"), einstieg1_2 = structure(c(5L,
5L, 5L, 4L, 5L, 5L, 5L, 5L, 5L, 5L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor"), einstieg1_3 = structure(c(2L,
4L, 5L, 5L, 4L, 4L, 5L, 4L, 4L, 4L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor"), einstieg1_4 = structure(c(1L,
4L, 2L, 2L, 2L, 1L, 3L, 3L, 2L, 3L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor"), einstieg1_5 = structure(c(1L,
2L, 2L, 4L, 2L, 1L, 4L, 2L, 2L, 5L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor"), einstieg1_6 = structure(c(1L,
1L, 1L, 2L, 1L, 1L, 2L, 1L, 1L, 1L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor"), einstieg1_7 = structure(c(4L,
3L, 4L, 1L, 3L, 6L, 2L, 2L, 2L, 6L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor"), einstieg1_8 = structure(c(4L,
4L, 4L, 2L, 2L, 4L, 1L, 6L, 2L, 6L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor"), einstieg1_9 = structure(c(3L,
2L, 2L, 5L, 3L, 5L, 2L, 3L, 4L, 4L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor"), einstieg1_10 = structure(c(5L,
5L, 2L, 4L, 4L, 5L, 3L, 5L, 4L, 5L), .Label = c("Stimme überhaupt nicht zu",
"Stimme eher nicht zu", "Weder noch", "Stimme eher zu", "Stimme voll und ganz zu",
"Weiß nicht/keine Angabe "), class = "factor")), row.names = c(NA,
10L), class = "data.frame")
# And the for loop for plotting
for (i in seq(1, length(data), 2))
print(plot(likert(data[ ,i:(i 1)])))
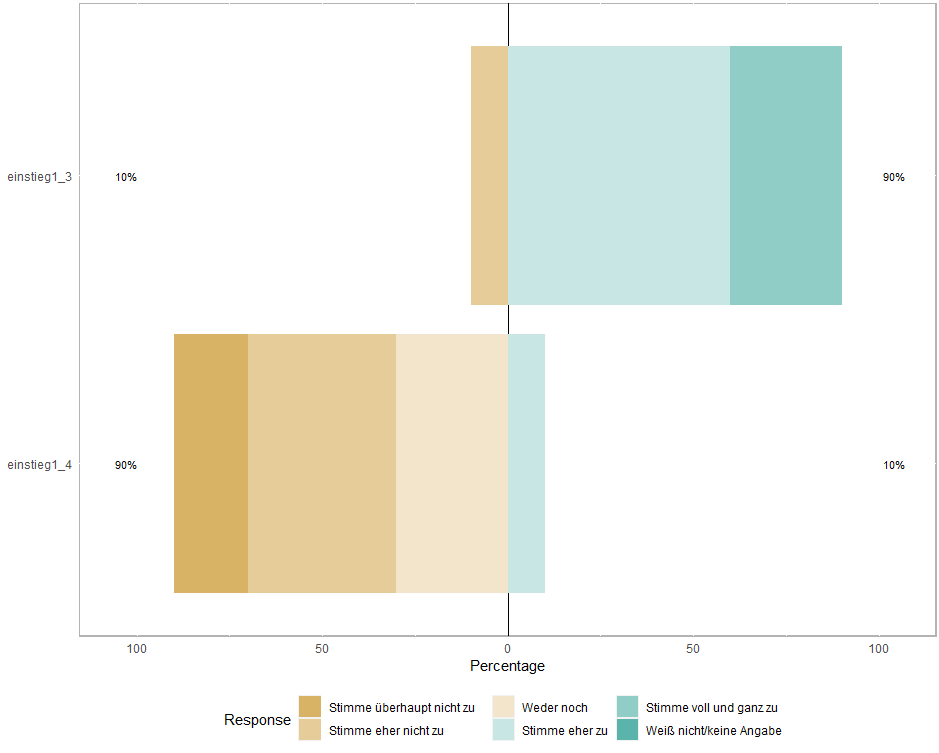
When plotting this the code of the column names appears on the right-hand side as the question. Instead, I would like the questions from another data frame to appear.
# Example data for questions / statements
questions <- structure(list(code = c("einstieg1_1", "einstieg1_2", "einstieg1_3",
"einstieg1_4", "einstieg1_5", "einstieg1_6", "einstieg1_7", "einstieg1_8",
"einstieg1_9", "einstieg1_10"), Frage = c("Statement a",
"Statement b",
"Statement c",
"Statement d",
"Statement e",
"Statement f",
"Statement g",
"Statement h",
"Statement i",
"Statement j"
)), row.names = c(NA, -10L), class = c("tbl_df", "tbl", "data.frame"
))
And I have another question. I have 6 levels: "Stimme eher zu", and "Stimme voll und ganz zu" are positive, "Stimme überhaupt nicht zu" and "Stimme eher nicht zu" are negative, "Weder noch" is neutral and "Weiß Nicht/keine Angabe" which is I don't know or no response. At the moment "Weder noch" is automatically counted as negative and "Weiß Nicht/keine Angabe" as positive.
How can I show a correct Likert-scale with "Weder noch" as a neutral level at the center? And what to do with a no reponse/i don't know level? I was thinking about excluding it, but therefore e.g. depicting the sample size to not use any information about how many people answered the question...? Or do you have another idea how that answer could be included in the plot? Well, I hope you can understand what I am trying to do... Thanks for your help!
CodePudding user response:
I didn't want to install the likert package so I used ggplot2. I hope this gets you close or points you in the right direction.
library(ggplot2)
# using lapply
lapply(seq_along(data), \(x) {
title = questions$Frage[which(names(data)[x] == questions$code)]
ggplot(data = NULL, aes(x = data[[x]]))
geom_bar()
labs(title = title,
x = "Response")
})
# using a for loop
for (x in seq_along(data)) {
title = questions$Frage[which(names(data)[x] == questions$code)]
p <-
ggplot(data = NULL, aes(x = data[[x]]))
geom_bar()
labs(title = title,
x = "Response")
print(p)
}
The 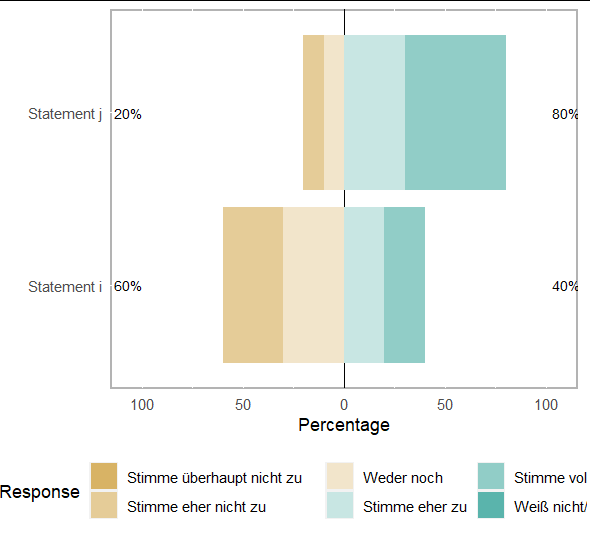
I prefer to use lapply and to assign the plots to a list for later examination, but you could also use the additional lines in your loop.
Regarding your second question, you should set "weiß nicht" to NA. This way "weder noch" will automatically be used as the centre. Here is a simple solution with for-loop:
data_r <- data
for(i in 1:ncol(data_r)) {
levels(data_r[,i])[levels(data_r[,i])=="Weiß nicht/keine Angabe "] <- NA
}
likertplots_r <- lapply(seq(1, length(data), 2), function(i) {
plot(likert(data_r[ ,i:(i 1)]), type="bar")
scale_x_discrete(breaks=questions[i:(i 1),"code"],
labels=questions[i:(i 1),"Frage"])
}
)
likertplots_r[[5]]
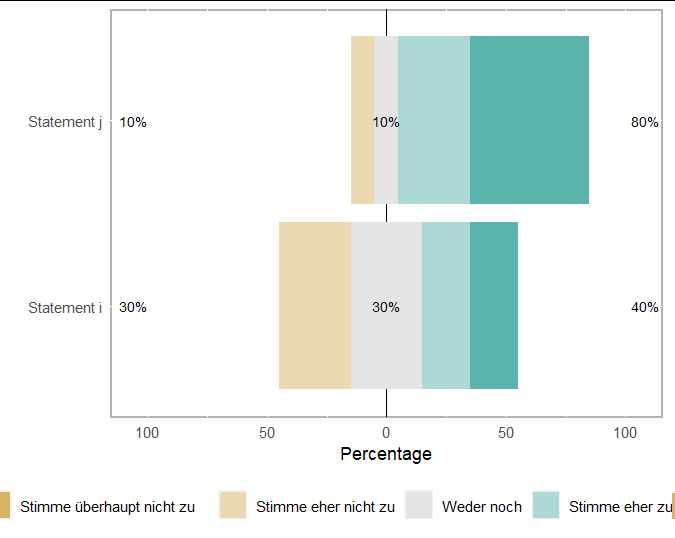
You can use additional labelling commands from ggplot2 to change e.g. all text in the plot to German.