I have two dataframes like as shown below
import numpy as np
import pandas as pd
from numpy.random import default_rng
rng = default_rng(100)
cdf = pd.DataFrame({'Id':[1,2,3,4,5],
'grade': rng.choice(list('ACD'),size=(5)),
'dash': rng.choice(list('PQRS'),size=(5)),
'dumeel': rng.choice(list('QWER'),size=(5)),
'dumma': rng.choice((1234),size=(5)),
'target': rng.choice([0,1],size=(5))
})
tdf = pd.DataFrame({'Id': [1,1,1,1,3,3,3],
'feature': ['grade=Rare','dash=Q','dumma=rare','dumeel=R','dash=Rare','dumma=rare','grade=D'],
'value': [0.2,0.45,-0.32,0.56,1.3,1.5,3.7]})
My objective is to
a) Replace the Rare or rare values in feature column of tdf dataframe by original value from cdf dataframe.
b) To identify original value, we can make use of the string before = Rare or =rare or = rare etc. That string represents the column name in cdf dataframe (from where original value to replace rare can be found)
I was trying something like the below but not sure how to go from here
replace_df = cdf.merge(tdf,how='inner',on='Id')
replace_df ["replaced_feature"] = np.where(((replace_df["feature"].str.contains('rare',regex=True)]) & (replace_df["feature"].str.split('='))])
I have to apply this on a big data where I have million rows and more than 1000 replacements to be made like this.
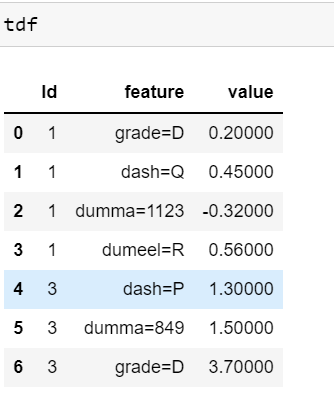
I expect my output to be like as shown below
CodePudding user response:
Here is one possible approach using MultiIndex.map to substitute values from cdf into tdf:
s = tdf['feature'].str.split('=')
m = s.str[1].isin(['rare', 'Rare'])
v = tdf[m].set_index(['Id', s[m].str[0]]).index.map(cdf.set_index('Id').stack())
tdf.loc[m, 'feature'] = s[m].str[0] '=' v.astype(str)
print(tdf)
Id feature value
0 1 grade=D 0.20
1 1 dash=Q 0.45
2 1 dumma=1123 -0.32
3 1 dumeel=R 0.56
4 3 dash=P 1.30
5 3 dumma=849 1.50
6 3 grade=D 3.70
CodePudding user response:
# list comprehension to find where rare is in the feature col
tdf['feature'] = [x if y.lower()=='rare' else x '=' y for x,y in tdf['feature'].str.split('=')]
# create a mask where feature is in columns of cdf
mask = tdf['feature'].isin(cdf.columns)
# use loc to filter your frame and use merge to join cdf on the id and feature column - after you use stack
tdf.loc[mask, 'feature'] = tdf.loc[mask, 'feature'] '=' tdf.loc[mask].merge(cdf.set_index('Id').stack().to_frame(),
right_index=True, left_on=['Id', 'feature'])[0].astype(str)
Id feature value
0 1 grade=D 0.20
1 1 dash=Q 0.45
2 1 dumma=1123 -0.32
3 1 dumeel=R 0.56
4 3 dash=P 1.30
5 3 dumma=849 1.50
6 3 grade=D 3.70
CodePudding user response:
My feeling is there's no need to look for Rare values.
Extract the column name from tdf to lookup in cdf. After, flatten your cdf dataframe to extract the right values:
r = tdf.set_index('Id')['feature'].str.split('=').str[0].str.lower()
tdf['feature'] = r.values '=' cdf.set_index('Id').unstack() \
.loc[zip(r.values, r.index)] \
.astype(str).values
Output:
>>> tdf
Id feature value
0 1 grade=D 0.20
1 1 dash=Q 0.45
2 1 dumma=1123 -0.32
3 1 dumeel=R 0.56
4 3 dash=P 1.30
5 3 dumma=849 1.50
6 3 grade=A 3.70
>>> r
Id # <- the index is the row of cdf
1 grade # <- the values are the column of cdf
1 dash
1 dumma
1 dumeel
3 dash
3 dumma
3 grade
Name: feature, dtype: object