The cluster is HDInsight 4.0 and has 250 GB RAM and 75 VCores.
I am running only one job and the cluster is always allocating 66 GB, 7 VCores and 7 Containers to the job even though we have 250 GB and 75 VCores available for use. This is not particular to one job. I have ran 3 different jobs and all have this issue. when I run 3 jobs in parallel , the cluster is still allocating 66 GB RAM to each job. Looks like there is some static setting configured.

The following is the queue setup
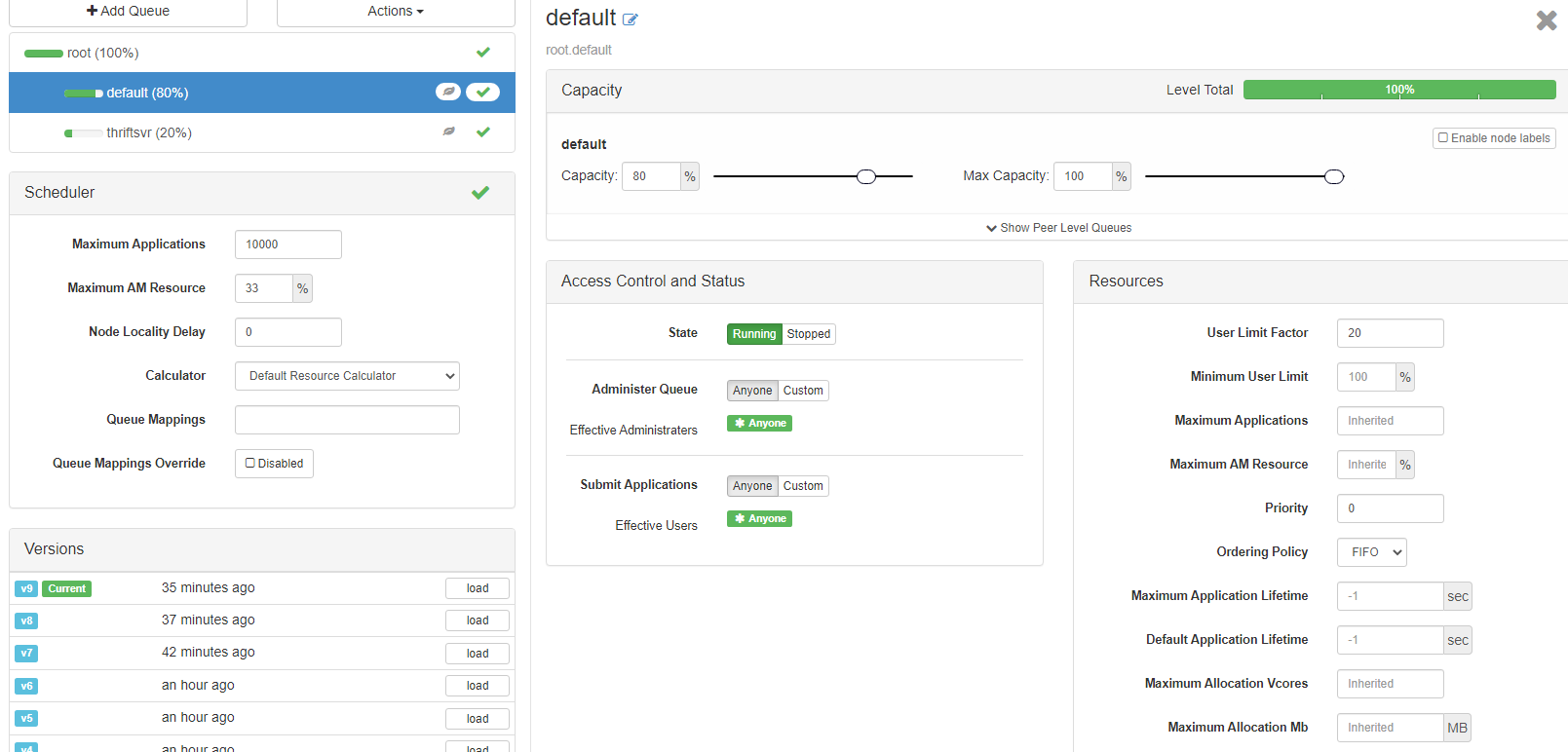
I am using a tool called Talend(ETL tool similar to informatica) where I have a GUI to create a job . The tool is eclipse based and below is the code generated for spark configuration. This is then given to LIVY for submission in the cluster.
sparkConfiguration.set("spark.hadoop.talendStudioTimeZone", java.util.TimeZone.getDefault().getID());
sparkConfiguration.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
sparkConfiguration.set("spark.kryo.registrator", TalendKryoRegistrator.class.getName());
sparkConfiguration.set("spark.yarn.submit.waitAppCompletion", "true");
tuningConf.put("spark.yarn.maxAppAttempts", "1");
tuningConf.put("spark.scheduler.mode", "FIFO");
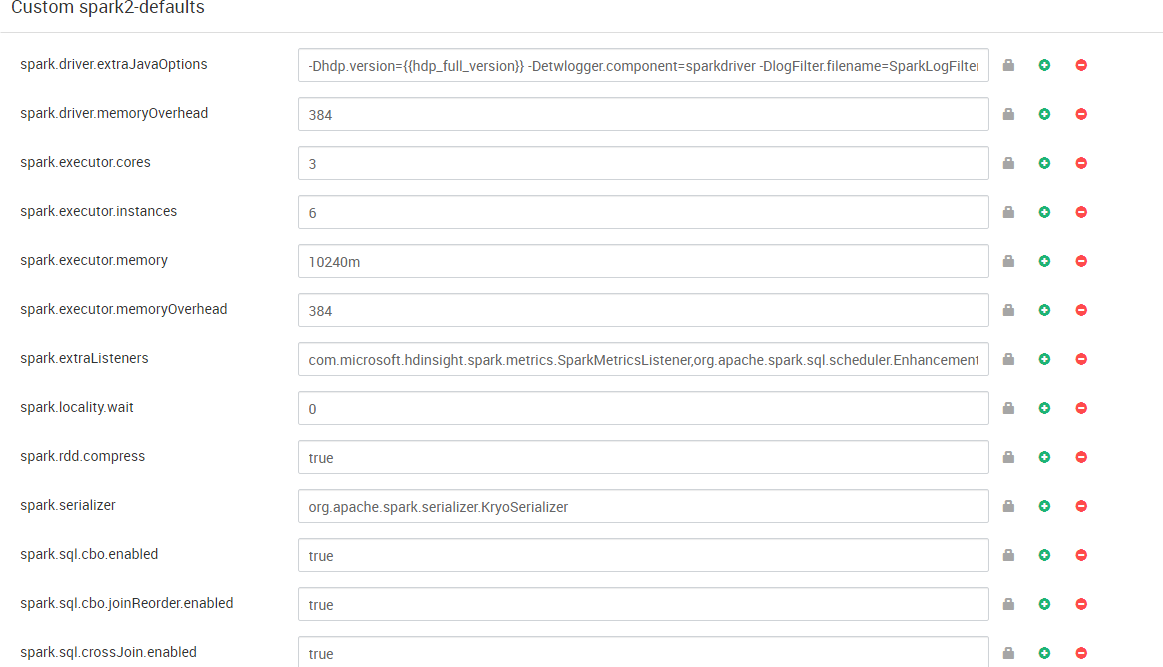
This is the screen shot of spark defaults
CodePudding user response:
The behavior is expected as 6 execuors * 10 GB per executor memory = 60G.
If want to use allocate more resources, try to increase exeucotr number such as 24