I am loading data from .csv files to Pandas dataframes. The data is from meteorological stations and has a "date and time" column. The problem arises when converting that column from string to datetime type, for some reason the data from other columns also changes to zeros or other values that I do not understand.
# first load the data
dique_aforador = pd.read_csv(obs_path 'Altura_diqueAforador_Estacion-4216.csv', sep=';', low_memory=False, skip_blank_lines=True, header=1).dropna(how='all')
# Look at the data
dique_aforador
Fecha y Hora Altura [m]
0 19/12/2019 13:00 0.00
1 19/12/2019 14:00 0.00
2 19/12/2019 15:00 0.00
3 19/12/2019 16:00 0.00
4 19/12/2019 17:00 0.00
... ... ...
14778 08/02/2022 15:00 1.34
14779 08/02/2022 16:00 1.34
14780 08/02/2022 17:00 1.33
14781 08/02/2022 18:00 1.33
14782 08/02/2022 19:00 1.33
# Plot the data as is
dique_aforador.plot(x='Fecha y Hora', rot=45)
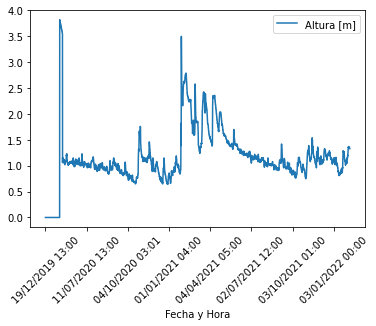
# But when I change the 'Fecha y Hora' column to datetime
dique_aforador['Fecha y Hora'] = pd.to_datetime(dique_aforador['Fecha y Hora'])
# This happens:
dique_aforador.plot(x='Fecha y Hora', rot=45)
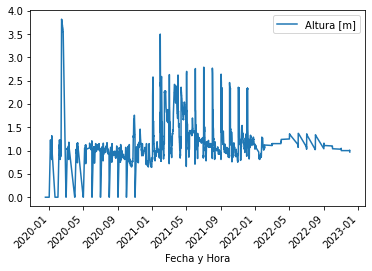
Looks like several entries of the Altura [m] column are replaced by zero or other random values and I do not understand what is happening. I have also tried other equivalent ways of doing the conversion to datetime and I get the same issue with all of them (using the .astype('datetime64[ns]') method, adding parse_dates=['Fecha y Hora'] when loading the data, etc.). This also happens when using meteorological station data from other sources, so I think it is not dataset-dependent and has to do with something related to the datetime conversion. Any tips on how to solve this?
CodePudding user response:
Have you tried adding the infer_date_format option to pandas.to_datetime?
Something like this:
dique_aforador['Fecha y Hora'] = pd.to_datetime(dique_aforador['Fecha y Hora'], infer_datetime_format=True)
Pandas can take the first value in your date field and infer the remaining from it