I have a dataset with a set of columns I want to sum for each row. The columns in question all follow a specific naming pattern that I have been able to group in the past via the .sum() function:
pd.DataFrame.sum(data.filter(regex=r'_name$'),axis=1)
Now, I need to complete this same function, but, when grouped by a value of a column:
data.groupby('group').sum(data.filter(regex=r'_name$'),axis=1)
However, this does not appear to work as the .sum() function now does not expect any filtered columns. Is there another way to approach this keeping my data.filter() code?
Example toy dataset. Real dataset contains over 500 columns where all columns are not cleanly ordered:
toy_data = ({'id':[1,2,3,4,5,6],
'group': ["a","a","b","b","c","c"],
'a_name': [1,6,7,3,7,3],
'b_name': [4,9,2,4,0,2],
'c_not': [5,7,8,4,2,5],
'q_name': [4,6,8,2,1,4]
})
df = pd.DataFrame(toy_data, columns=['id','group','a_name','b_name','c_not','q_name'])
Edit: Missed this in original post. My objective is to get a variable ;sum" of the summation of all the selected columns as shown below:
CodePudding user response:
You can filter first and then pass df['group'] instead group to groupby, last add sum column by DataFrame.assign:
df1 = (df.filter(regex=r'_name$')
.groupby(df['group']).sum()
.assign(sum = lambda x: x.sum(axis=1)))
ALternative is filter columns names and pass after groupby:
cols = df.filter(regex=r'_name$').columns
df1 = df.groupby('group')[cols].sum()
Or:
cols = df.columns[df.columns.str.contains(r'_name$')]
df1 = df.groupby('group')[cols].sum().assign(sum = lambda x: x.sum(axis=1))
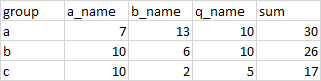
print (df1)
a_name b_name q_name sum
group
a 7 13 10 30
b 10 6 10 26
c 10 2 5 17