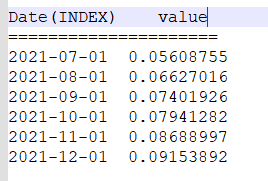
I have a DF like below with Date value as Index
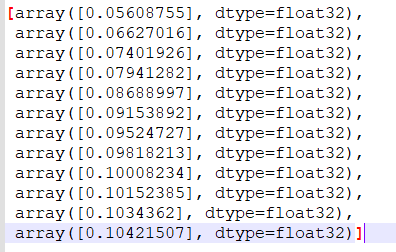
I have the 6 values in an array and i have added 6 more values to the same array like:
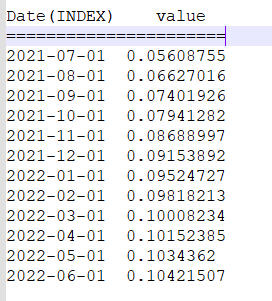
Now i need to append the whole 12 values to the same array with new Date index value like below:
When i try to set the value using test['value'] = new_values , it is giving the below error:
ValueError: Length of values (18) does not match length of index (12)
Please help
CodePudding user response:
It's not clear from your question how exactly you're getting the error you mentioned because you didn't show how you created the DataFrame and the arrays.
It's unusual to resize a DF by simply reassigning a single column, which should sound natural to you if you think about how other columns should behave in that situation, in the case where a DF has those. Instead, to resize a DF we usually use one of the specialized functions pd.concat, pd.DataFrame.merge or pd.DataFrame.join.
I'd approach this situation using pd.concat; more specifically creating a new DataFrame with just the new values and index and concatenating it with the old one.
Recreating the scenario
Here's an attempt to recreate something similar to your starting point; i.e. the initial DF.
import numpy as np
import pandas as pd
init_index = np.arange(
np.datetime64("2021-07"),
np.datetime64("2022"),
np.timedelta64(1, "M")
)
init_values = np.random.rand(6, 1)
init_df = pd.DataFrame(
data=values,
index=index,
columns=["values"]
)
# >>> init_df
# values
# 2021-07-01 0.002215
# 2021-08-01 0.064340
# 2021-09-01 0.595143
# 2021-10-01 0.822837
# 2021-11-01 0.568886
# 2021-12-01 0.382716
And here's the same attempt at recreating your new_values array. I'm assuming, from the image you included, that it's not a simple list of values, but a list of lists of values, each containing a single value (i.e. a 2-dimensional array whose shape is (6, 1)).
new_values = np.concatenate((init_df["values"], np.random.rand(6,1)))
# >>> all_values
# array([[0.00221483],
# [0.0643404 ],
# [0.59514306],
# [0.82283698],
# [0.56888584],
# [0.38271593],
# [0.23964758],
# [0.90354089],
# [0.12688775],
# [0.53930331],
# [0.99087057],
# [0.12583731]])
Hopefully that's close enough to what you're working with.
Actual solution
For my approach, we create a new DF with just the new data and the new dates:
all_values = new_values
new_values = all_values[7:]
new_index = np.arange(
np.datetime64("2021"),
np.datetime64("2021-07"),
np.timedelta64(1, "M")
)
new_df = pd.DataFrame(
data=new_values,
index=new_index,
columns=["values"]
)
# >>> new_df
# values
# 2021-01-01 0.239648
# 2021-02-01 0.903541
# 2021-03-01 0.126888
# 2021-04-01 0.539303
# 2021-05-01 0.990871
# 2021-06-01 0.125837
And then concatenate both DFs using pd.concat:
final_df = pd.concat([init_df, new_df])
# >>> final_df
# values
# 2021-07-01 0.002215
# 2021-08-01 0.064340
# 2021-09-01 0.595143
# 2021-10-01 0.822837
# 2021-11-01 0.568886
# 2021-12-01 0.382716
# 2021-01-01 0.239648
# 2021-02-01 0.903541
# 2021-03-01 0.126888
# 2021-04-01 0.539303
# 2021-05-01 0.990871
# 2021-06-01 0.125837