Consider the following dataframe:
import pandas as pd
from pandas import DataFrame
df = pd.DataFrame({'ID': ['A','A','A','B','B','B','C','C','C'], 'YEAR': [2000,2001,2002,2007,2008,2009,2015,2016,2017],
'ITEM-A': [100,200,300,700,800,900,1100,1200,1300], 'ITEM-B':[4000,5000,6000,3000,3500,4000,500,600,800]})
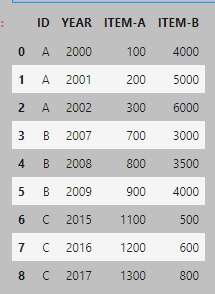
I want to group by the ID and sum ITEM-A and ITEM-B, but I also want to add 2 columns to include the min and max year (respectively) for each group. My ultimate goal is to end up with a dataframe that looks something like this:
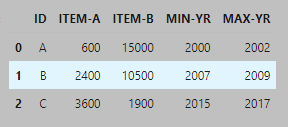
What is the best way to accomplish this? My initial thought is to add the two new columns and populate each row with the min and max which should look something like this:
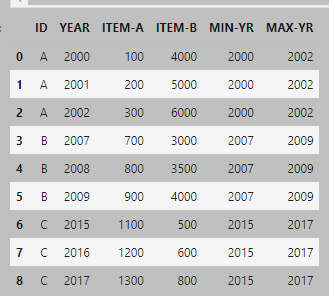
Then I could use a groupby/sum function to get the totals and drop the YEAR column.
I tried this code to add the columns but all I got were NaN values:
df['MIN-YR'] = df.groupby('ID')['YEAR'].min()
df['MAX-YR'] = df.groupby('ID')['YEAR'].max()
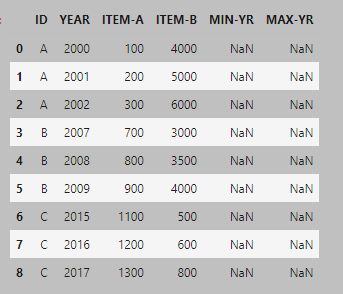
Is there a better way to accomplish what I'm trying to do? Am I on the right track? If so, what is causing the NaN values in the MIN-YR and MAX-YR columns?
Thanks!
CodePudding user response:
You could use agg and specify what function(s) to use for the aggregate per column:
(
df
.groupby("ID")
.agg({"YEAR": ["min", "max"], "ITEM-A": "sum", "ITEM-B": "sum"})
)
This will generate the following table:
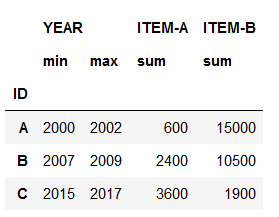
CodePudding user response:
You can do it like this, using Named Aggregation, without multiindex column headers nor renaming:
df.groupby('ID', as_index=False).agg(**{'ITEM-A':('ITEM-A','sum'),
'ITEM-B':('ITEM-B','sum'),
'MIN-YR':('YEAR', 'min'),
'MAX-YR':('YEAR','max')})
Output:
ID ITEM-A ITEM-B MIN-YR MAX-YR
0 A 600 15000 2000 2002
1 B 2400 10500 2007 2009
2 C 3600 1900 2015 2017