This is an example of the sitemap (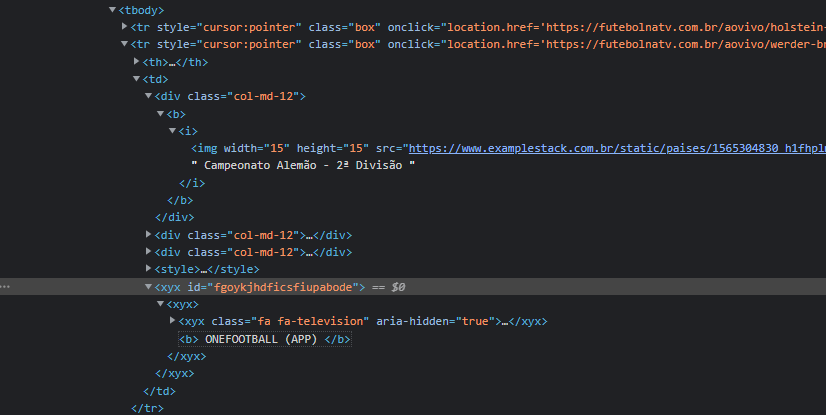
If I use this XPATH:
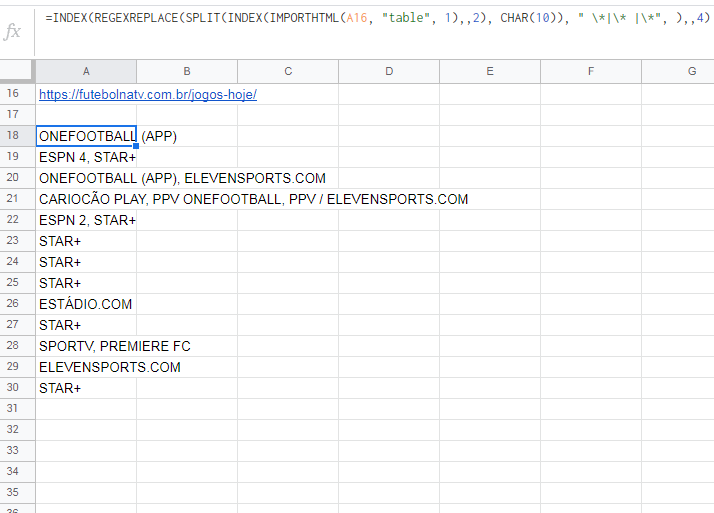
=IMPORTXML("https://futebolnatv.com.br/jogos-hoje/","//tbody/tr/td//b")
I will retrieve two values:
Campeonato Alemão - 2ª Divisão
ONEFOOTBALL (APP)
The XPATH models that I tried to use to get only the ONEFOOTBALL (APP) value were these:
=IMPORTXML("https://futebolnatv.com.br/jogos-hoje/","//tbody/tr/td//b[not(contains(#src,'www.'))]")
=IMPORTXML("https://futebolnatv.com.br/jogos-hoje/","//tbody/tr/td//b[not(contains(@i,''))]")
=IMPORTXML("https://futebolnatv.com.br/jogos-hoje/","//tbody/tr/td//b[not(contains(@img,''))]")
I can't use the path working with <xyx> because every page this value changes, it could be <xwtrui> or something else random.
How could I manage to collect this value ONEFOOTBALL (APP) on second <b> without ending up also taking the value of this first that in the example is the Campeonato Alemão - 2ª Divisão?
CodePudding user response:
see:
=INDEX(REGEXREPLACE(SPLIT(INDEX(IMPORTHTML(A16, "table", 1),,2), CHAR(10)), " \*|\* |\*", ),,4)