For example if I have a DataFrame that looks like this
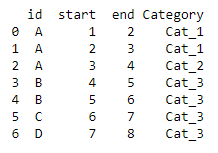
For the same id and Category, I would like to keep only the first start and last end number and eliminate the middle ones. For example, for row 0 and 1, since their id are both A and category are both Cat_1, the start would be 1 and end would be 3.
The expected output would look like this:
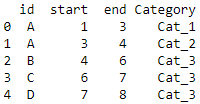
Feel free to use the following code to explore:
import pandas as pd
data = {'id': ['A','A','A', 'B', 'B', 'C' , 'D'],
'start': [1,2,3,4,5,6,7],
'end': [2,3,4,5,6,7,8],
'Category':['Cat_1', 'Cat_1', 'Cat_2' , 'Cat_3', 'Cat_3', 'Cat_3', 'Cat_3']
}
df = pd.DataFrame(data)
CodePudding user response:
You could use groupby agg where you call first on "start" and last on "end":
out = df.groupby(['id','Category'], as_index=False).agg({'start':'first', 'end':'last'})
Output:
id Category start end
0 A Cat_1 1 3
1 A Cat_2 3 4
2 B Cat_3 4 6
3 C Cat_3 6 7
4 D Cat_3 7 8