I have the data like this and I want to make age categories based on P_ID column and store it in a new column AgeCatg. I followed 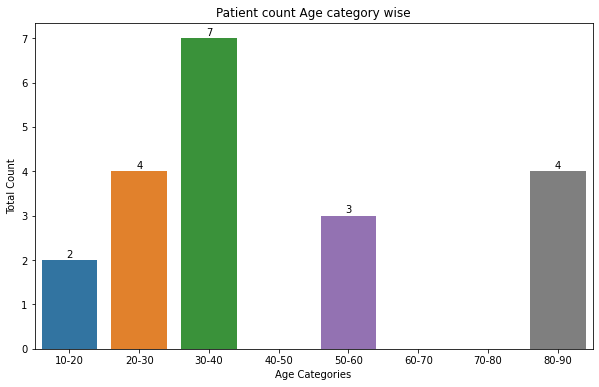
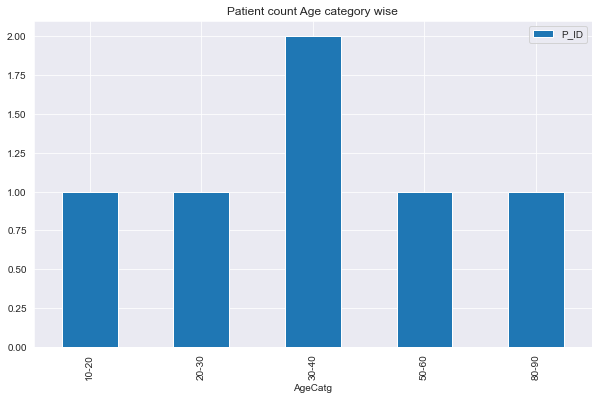
Here, the code is plotting total number of rows that fall in the category, but I want to plot patients counts, not the patient rows. Like, P_ID 3 and 6 lies in AgeCatg 30-40, so the graph should plot 2 above the bar, not the total number of rows that are 7. I think the problem is where I used pd.cut(). I tried the following but it gave wrong result.
x['AgeCatg'] = pd.cut(x.groupby('P_ID')['Age'].first(), np.arange(9, 90, 10), labels=[f'{x}-{x 10}' for x in np.arange(10, 89, 10)])
Please help. Thanks.
Update
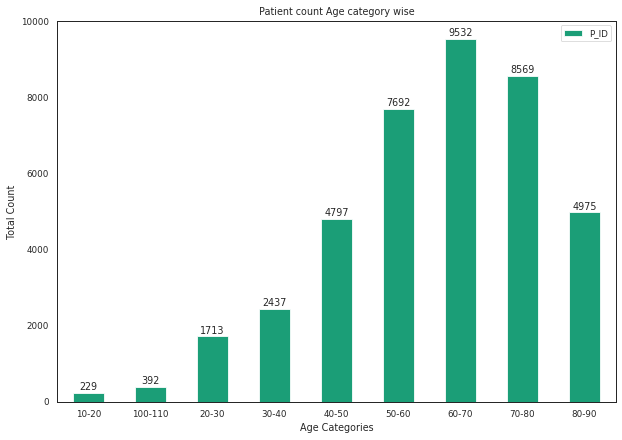
After P. Pinho Answer, I applied the code on my real data. It worked perfectly. However There is a little issue on x-axis labels of graph. Please have a look and let me know how it can be like 10-20, 20-30, 30-40 ... instead of 10-20, 100-110, 20-30, ... Thanks
CodePudding user response:
Try this:
df = pd.DataFrame({'Age' :[51,51,51,28,28,28,28,35,35,35,35,89,89,89,89,14,14,38,38,38],
'P_ID':[1,1,1,2,2,2,2,3,3,3,3,4,4,4,4,5,5,6,6,6]})
EDIT 1: Ir order to create the AgeCatg column I created a list populated by a fstring. The // operator returns the floor division. For instance: 51//10 = 5, if we mutiply by 10, we get the decimal we are looking for. If we add 10, we have the proper time window.
df['AgeCatg'] = [f'{i//10*10}-{i//10*10 10}' for i in df['Age']]
Output:
df
Age P_ID AgeCatg
0 51 1 50-60
1 51 1 50-60
2 51 1 50-60
3 28 2 20-30
4 28 2 20-30
5 28 2 20-30
6 28 2 20-30
7 35 3 30-40
8 35 3 30-40
9 35 3 30-40
10 35 3 30-40
11 89 4 80-90
12 89 4 80-90
13 89 4 80-90
14 89 4 80-90
15 14 5 10-20
16 14 5 10-20
17 38 6 30-40
18 38 6 30-40
19 38 6 30-40
Graph:
df.groupby('AgeCatg').agg({'P_ID': 'nunique'}).plot(kind='bar', figsize=(10,6), title='Patient count Age category wise');
Output: