My initial dataframe looks as follows:
| User | License | Status | Start-Date | End-Date |
|---|---|---|---|---|
| A | xy | access | 10.01.2022 | 13.01.2022 |
| B | xy | access | 11.01.2022 | 14.01.2022 |
| C | xy | access | 11.01.2022 | 14.01.2022 |
| A | xy | access | 12.01.2022 | 15.01.2022 |
| A | xy | access | 14.01.2022 | 17.01.2022 |
| B | xy | access | 21.01.2022 | 24.01.2022 |
| A | xy | access | 21.01.2022 | 24.01.2022 |
There are three users (a, b, c) who request a license on different days. In principle, the end date is always three days later than the start date due to the fact that a license is locked for a period of 3 days.
For example, if user A accesses again within these three days, the period is extended again by three days.
My (ultimate) goal is to get a graph like the following:
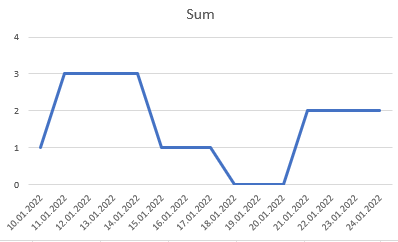
So i can see how many licenses were blocked.
But this is just my goal in a later step. I thought the best way to achieve an output like this would be the following table (dataframe) in a next step and just plotting Sum over Date:
| Date | A | B | C | Sum |
|---|---|---|---|---|
| 10.01.2022 | 1 | 0 | 0 | 1 |
| 11.01.2022 | 1 | 1 | 1 | 3 |
| 12.01.2022 | 1 | 1 | 1 | 3 |
| 13.01.2022 | 1 | 1 | 1 | 3 |
| 14.01.2022 | 1 | 1 | 1 | 3 |
| 15.01.2022 | 1 | 0 | 0 | 1 |
| 16.01.2022 | 1 | 0 | 0 | 1 |
| 17.01.2022 | 1 | 0 | 0 | 1 |
| 18.01.2022 | 0 | 0 | 0 | 0 |
| 19.01.2022 | 0 | 0 | 0 | 0 |
| 20.01.2022 | 0 | 0 | 0 | 0 |
| 21.01.2022 | 1 | 1 | 0 | 2 |
| 22.01.2022 | 1 | 1 | 0 | 2 |
| 23.01.2022 | 1 | 1 | 0 | 2 |
| 24.01.2022 | 1 | 1 | 0 | 2 |
(But I am not sure if this is the best way to achieve it.)
Would that be possible with pandas? If yes, how? Tbh I have no clue. I hope I didn't explain the question too complicated.
So I'm only concerned with the second dataframe, how I get it, not the graph itself.
CodePudding user response:
From the graph it seems like you only care about the total number of active licenses per day. So, I'm providing an answer in that context. If you need the breakup at user level then it has to be changed a bit.
First, let's import the packages and create a sample dataframe. I've added one extra row for User A at the end to solidify some of the core concepts. Also, I'm explicitly changing the start and end date columns from string to date type.
import pandas as pd
import datetime
data_dict = {
'User': ['A', 'B', 'C', 'A', 'A', 'B', 'A', 'A'],
'License': ['xy', 'xy', 'xy', 'xy', 'xy', 'xy', 'xy', 'xy'],
'Status': ['access', 'access', 'access', 'access', 'access', 'access', 'access', 'access'],
'Start-Date': ['10.01.2022', '11.01.2022', '11.01.2022', '12.01.2022', '14.01.2022', '21.01.2022', '21.01.2022', '16.01.2022'],
'End-Date': ['13.01.2022', '14.01.2022', '14.01.2022', '15.01.2022', '17.01.2022', '24.01.2022', '24.01.2022', '20.01.2022']
}
pdf = pd.DataFrame.from_dict(data=data_dict)
pdf['Start-Date'] = pd.to_datetime(pdf['Start-Date'], format='%d.%m.%Y')
pdf['End-Date'] = pd.to_datetime(pdf['End-Date'], format='%d.%m.%Y')
The dataframe will be like the one below.
User License Status Start-Date End-Date
A xy access 2022-01-10 2022-01-13
B xy access 2022-01-11 2022-01-14
C xy access 2022-01-11 2022-01-14
A xy access 2022-01-12 2022-01-15
A xy access 2022-01-14 2022-01-17
B xy access 2022-01-21 2022-01-24
A xy access 2022-01-21 2022-01-24
A xy access 2022-01-16 2022-01-20
The tricky part here is to merge the overlappihg intervals for each user into a bigger interval. I've borrowed the core ideas from this SO post. The idea is to first group your data per user (and other additional columns except dates). Then Within each group we need to further group the data into subgroups, so that the overlapping intervals per user belong to the same sub-group. Once we get that, then all we need is to extract the min start-date and max end-date per subgroup and assign that as the new start and end dates for all entries in that subgroup. In the end, we'll drop the duplicates because it's redundant info.
The next part is pretty straight-forward. we create a new dataframe with only dates that ranges between global start and end dates. Then we join these two dataframes and sum up all the licenses per day.
def f(df_grouped):
df_grouped = df_grouped.sort_values(by='Start-Date').reset_index(drop=True)
df_grouped["group"] = (df_grouped["Start-Date"] > df_grouped["End-Date"].shift()).cumsum()
grp = df_grouped.groupby("group")
df_grouped['New-Start-Date'] = grp['Start-Date'].transform('min')
df_grouped['New-End-Date'] = grp['End-Date'].transform('max')
return df_grouped.drop("group", axis=1)
pdf2 = pdf.groupby(['User', 'License', 'Status']).apply(f).drop(['Start-Date', 'End-Date'], axis=1).drop_duplicates()
pdf2 contains the refined start and end dates per user, as we can see below.
User License Status New-Start-Date New-End-Date
User License Status
A xy access 0 A xy access 2022-01-10 2022-01-20
4 A xy access 2022-01-21 2022-01-24
B xy access 0 B xy access 2022-01-11 2022-01-14
1 B xy access 2022-01-21 2022-01-24
C xy access 0 C xy access 2022-01-11 2022-01-14
Let's create the new dataframe now, with date ranges.
num_days = (pdf['End-Date'].max() - pdf['Start-Date'].min()).days 1
# num_days = 15
min_date = pdf['Start-Date'].min()
pdf3 = pd.DataFrame.from_dict(data={'Dates': [min_date datetime.timedelta(days=n) for n in range(num_days)]})
pdf3 looks as follows:
Dates
2022-01-10
2022-01-11
2022-01-12
2022-01-13
2022-01-14
2022-01-15
2022-01-16
2022-01-17
2022-01-18
2022-01-19
2022-01-20
2022-01-21
2022-01-22
2022-01-23
2022-01-24
Let's now join these two dataframes, and remove bad rows:
pdf4 = pd.merge(pdf2, pdf3, how='cross')
def final_data_prep(start, end, date):
if date >= start and date <= end:
return 1
else:
return 0
pdf4['Num-License'] = pdf4[['New-Start-Date', 'New-End-Date', 'Dates']].apply(lambda x: final_data_prep(x[0],
x[1], x[2]), axis=1)
pdf4 looks as follows:
User License Status New-Start-Date New-End-Date Dates Num-License
0 A xy access 2022-01-10 2022-01-20 2022-01-10 1
1 A xy access 2022-01-10 2022-01-20 2022-01-11 1
2 A xy access 2022-01-10 2022-01-20 2022-01-12 1
3 A xy access 2022-01-10 2022-01-20 2022-01-13 1
4 A xy access 2022-01-10 2022-01-20 2022-01-14 1
... ... ... ... ... ... ... ...
70 C xy access 2022-01-11 2022-01-14 2022-01-20 0
71 C xy access 2022-01-11 2022-01-14 2022-01-21 0
72 C xy access 2022-01-11 2022-01-14 2022-01-22 0
73 C xy access 2022-01-11 2022-01-14 2022-01-23 0
74 C xy access 2022-01-11 2022-01-14 2022-01-24 0
Now, all we need to do is do a groupby per day, and voila!
pdf_final = pdf4[['Dates', 'User', 'License', 'Status', 'Num-License']].groupby('Dates')['Num-License'].sum().reset_index().sort_values(['Dates'], ascending=True).reset_index(drop=True)
# here's the final dataframe
Dates Num-License
0 2022-01-10 1
1 2022-01-11 3
2 2022-01-12 3
3 2022-01-13 3
4 2022-01-14 3
5 2022-01-15 1
6 2022-01-16 1
7 2022-01-17 1
8 2022-01-18 1
9 2022-01-19 1
10 2022-01-20 1
11 2022-01-21 2
12 2022-01-22 2
13 2022-01-23 2
14 2022-01-24 2
If you need to retain user level info as well, then just add the user col in the last groupby. Also, to replicate your results, remove the last row when creating the dataframe.