I am trying to get a multi level index and column pandas data frame from an excel file, but oddly it seems that it is skipping a row. Consider the following:
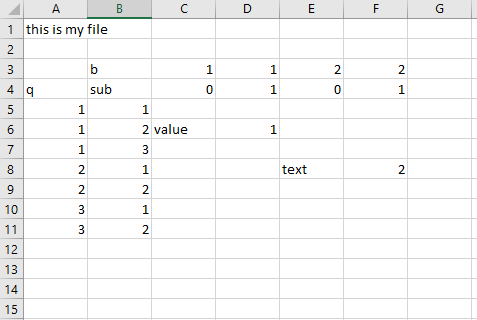
This is my code
df = pd.read_excel(r"https://buy-and-hold-strategy.s3.eu-central-1.amazonaws.com/example.xls",
skiprows=2,
sheet_name='Sheet1',
index_col=[0, 1],
header=[0, 1])
df.head()
returns
Out[46]:
b 1 2
sub 0 1 0 1
1 1
1 2 value 1.0 NaN NaN
3 NaN NaN NaN NaN
2 1 NaN NaN text 2.0
2 NaN NaN NaN NaN
3 1 NaN NaN NaN NaN
It seems that the first row of data 1.1 is stored as the index name:
df.index.names
Out[49]: FrozenList([1, 1])
CodePudding user response:
I think your excel file has a wrong structure.. maybe you can adjust the structure of the Excel file like this:
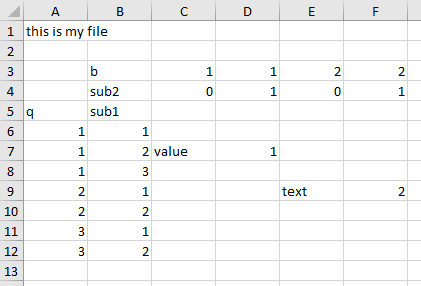
Afterwards you can read your file like you aready did:
df = pd.read_excel((r"https://buy-and-hold-strategy.s3.eu-central-1.amazonaws.com/example.xls",
skiprows=2,
sheet_name='Sheet1',
index_col=[0,1],
header=[0,1])
df.head()
And you get the following result:
df.head()
b 1 2
sub2 0 1 0 1
q sub1
1 1 NaN NaN NaN NaN
2 value 1.0 NaN NaN
3 NaN NaN NaN NaN
2 1 NaN NaN text 2.0
2 NaN NaN NaN NaN
CodePudding user response:
Since your problem comes from using index_col with multiple values (and that's what creates a multiindex), let's simplify the problem by not using an index. (Also, we don't need to modify the excel structure for this to work).
>>> df = pd.read_excel(r"https://buy-and-hold-strategy.s3.eu-central-1.amazonaws.com/example.xls",
skiprows=2,
sheet_name='Sheet1',
# index_col=[0], # No index over here
header=[0, 1])
Now, you can create the new index:
>>> df = df.set_index(df.columns[:2].tolist())
>>> df
1 2
0 1 0 1
(Unnamed: 0_level_0, q) (b, sub)
1 1 NaN NaN NaN NaN
2 value 1.0 NaN NaN
3 NaN NaN NaN NaN
2 1 NaN NaN text 2.0
2 NaN NaN NaN NaN