I am trying to extract book names from oreilly media website using python beautiful soup.
However I see that the book names are not in the page source html.
I am using this link to see the books:
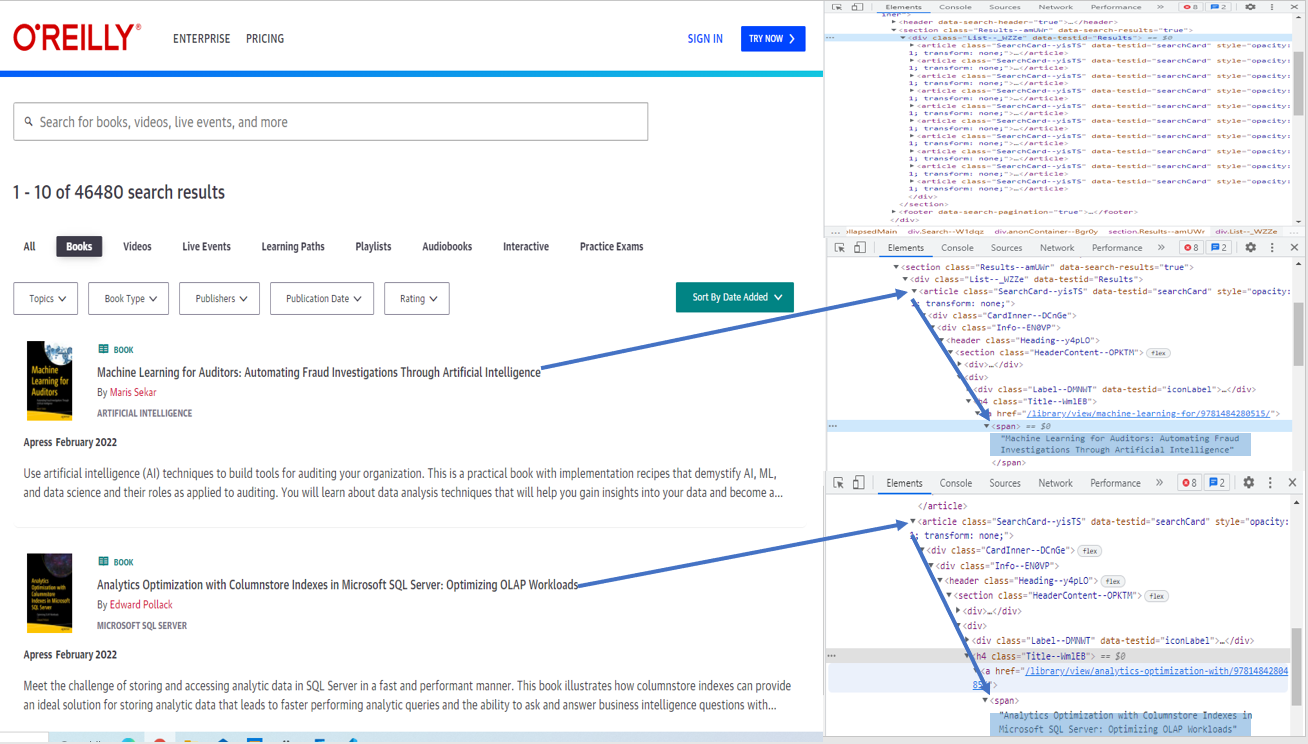
I looked at the page source but could not find the book names - maybe they are hidden inside some other links inside the main html.
I tried to open some of the links inside the html and searched for the book names but could not find anything.
is it possible to extract the first or second book names from the website using beautiful soup? if not is there any other python package that can do that? maybe selenium?
Or as a last resort any other tool...
CodePudding user response:
So if you investigate into network tab, when loading page, you are sending request to API
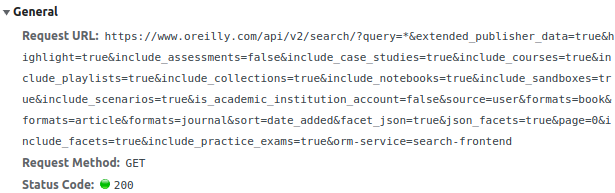
It returns json with books.
After some investigation by me, you can get your titles via
import json
import requests
response_json = json.loads(requests.get(
"https://www.oreilly.com/api/v2/search/?query=*&extended_publisher_data=true&highlight=true&include_assessments=false&include_case_studies=true&include_courses=true&include_playlists=true&include_collections=true&include_notebooks=true&include_sandboxes=true&include_scenarios=true&is_academic_institution_account=false&source=user&formats=book&formats=article&formats=journal&sort=date_added&facet_json=true&json_facets=true&page=0&include_facets=true&include_practice_exams=true&orm-service=search-frontend").text)
for book in response_json['results']:
print(book['highlights']['title'][0])
CodePudding user response:
To solve this issue you need to know beautiful soup can deal with websites that use plan html. so the the websites that use JavaScript in their page beautiful soup cant's get all page data that you looking for bcz you need a browser like to load the JavaScript data in the website. and here you need to use Selenium bcz it open a browser page and load all data of the page, and you can use both as a combine like this:
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import lxml
# This will make selenium run in backround
chrome_options = Options()
chrome_options.add_argument("--headless")
# You need to install driver
driver = webdriver.Chrome('#Dir of the driver' ,options=chrome_options)
driver.get('#url')
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
and with this you can get all data that you need, and dont forget to write this at end to quit selenium in background.
driver.quit()