I have a table with data like this:
Row Group Amount
1 Group A 20
… Group A 20
3000 Group A 20
3001 Group B 20
… Group B 20
6000 Group B 20
6001 Group C 20
… Group C 20
9000 Group C 20
And I want to order this data, like this:
Row Group Amount
1 Group A 20
2 Group B 20
3 Group C 20
4 Group A 20
5 Group B 20
6 Group C 20
7 Group A 20
8 Group B 20
9 Group C 20
…
9000 GroupC 20
How can I do this? I was thinking that maybe using a Windows function, but can't figure it out
CodePudding user response:
What about this logic ?
- you want groups of 3 lines A, B, C that need to be ordered somehow,
- within these groups ordering is simple A, then B, then C
Therefore you want to give each line the number of group it should belong to. To do so:
- separate the rows per group (A, B or C),
- give each row a number
- order all the rows in that number, then per group..
In SQL it gives:
SELECT
`Group`,
amount
FROM
`project.dataset.table`
ORDER BY
ROW_NUMBER() OVER(PARTITION BY `Group` ORDER BY ROW),
`Group`
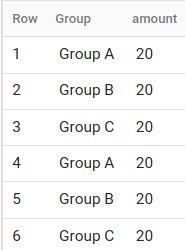
with some sample data it returns indeed:
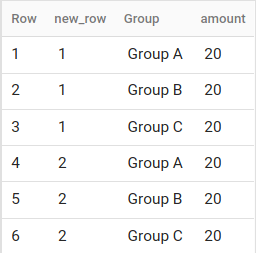
To further illustrate the effect of ROW_NUMBER:
SELECT
ROW_NUMBER() OVER(PARTITION BY `Group` ORDER BY ROW) AS new_row,
`Group`,
amount
FROM
sample
ORDER BY
ROW_NUMBER() OVER(PARTITION BY `Group` ORDER BY ROW),
`Group`
returns