I've the following dataset

The code is as follows:
df = structure(list(UID = structure(1:5, .Label = c("C001", "C002",
"C003", "C004", "C005"), class = "factor"), Shop_Code = structure(1:5, .Label = c("A",
"B", "C", "D", "E"), class = "factor"), Shop_District_Code = structure(1:5, .Label = c("AA",
"BB", "CC", "DD", "EE"), class = "factor"), Bread = c(5, 4.8,
4.5, 4.2, 5), Apple = c(3, 2.8, 3.1, 3.4, 3.2), Coke = c(3, 2.6,
2.8, 3, 3.1), Bread_1 = c(NA, NA, NA, 4.6, NA), Apple_1 = c(NA,
NA, NA, 2.6, NA), Coke_1 = c(NA, NA, NA, 2.2, NA), Bread_2 = c(NA,
NA, 4.6, NA, 5.1), Apple_2 = c(NA, NA, 3, NA, 3.3), Coke_2 = c(NA,
NA, 3, NA, 3.2), Bread_3 = c(NA, NA, 4.8, NA, NA), Apple_3 = c(NA,
NA, 2.7, NA, NA), Coke_3 = c(NA, NA, 2.6, NA, NA)), class = "data.frame", row.names = c(NA,
-5L))
Does anybody know how I can append the extended columns to the bottom as rows like the following table using pivot_wider/pivot_longer (or any other functions)?
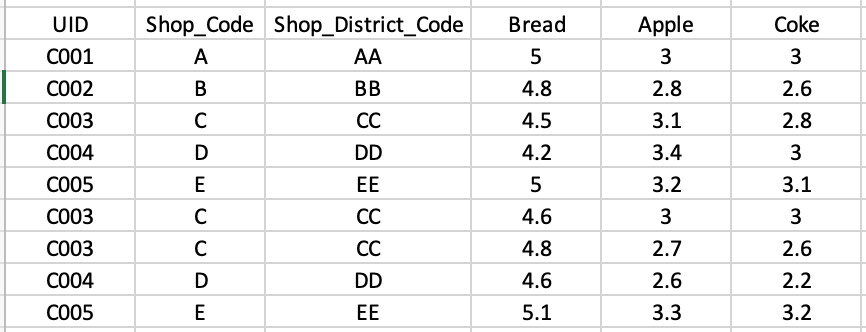
CodePudding user response:
You just need to pivot longer and then filter the NA rows. You can do that with
library(dplyr)
library(tidyr)
df %>%
pivot_longer(!UID:Shop_District_Code,
names_pattern="([^_] )(_?\\d*)",
names_to=c(".value", "grp")) %>%
select(-grp) %>%
filter(across(!UID:Shop_District_Code, ~!is.na(.x)))
which returns
UID Shop_Code Shop_District_Code Bread Apple Coke
<fct> <fct> <fct> <dbl> <dbl> <dbl>
1 C001 A AA 5 3 3
2 C002 B BB 4.8 2.8 2.6
3 C003 C CC 4.5 3.1 2.8
4 C003 C CC 4.6 3 3
5 C003 C CC 4.8 2.7 2.6
6 C004 D DD 4.2 3.4 3
7 C004 D DD 4.6 2.6 2.2
8 C005 E EE 5 3.2 3.1
9 C005 E EE 5.1 3.3 3.2
CodePudding user response:
pivot_longer(df, -(1:3),
names_to = '.value',
names_pattern = '([^_] )',
values_drop_na = TRUE)
# A tibble: 9 x 6
UID Shop_Code Shop_District_Code Bread Apple Coke
<fct> <fct> <fct> <dbl> <dbl> <dbl>
1 C001 A AA 5 3 3
2 C002 B BB 4.8 2.8 2.6
3 C003 C CC 4.5 3.1 2.8
4 C003 C CC 4.6 3 3
5 C003 C CC 4.8 2.7 2.6
6 C004 D DD 4.2 3.4 3
7 C004 D DD 4.6 2.6 2.2
8 C005 E EE 5 3.2 3.1
9 C005 E EE 5.1 3.3 3.2