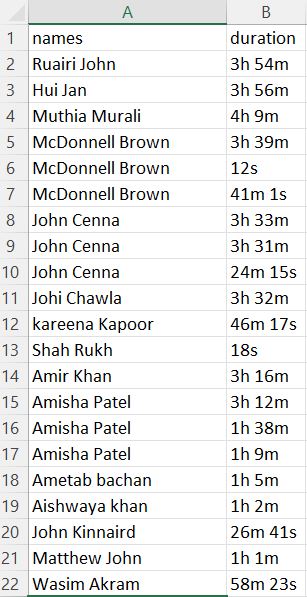
I have a CSV file having online Teams meeting data. It has two columns, one is "names" and the other with their duration of attendance during the meeting. I want to convert this information into a graph to quickly identify who remained for a long time in the meeting and who for less time. The duration column data is in this format, 3h 54m. This means it has the characters h and m in the column. See the picture below too.
Now how can I convert this data into decimal values like 3.54 or 234?
3.54 will mean hours and 234 will mean minutes in total. I am happy with any solution like either hour i.e. 3.54 or minutes 234.
Numpy or Pandas are both welcome.
CodePudding user response:
The conversion of the timestring can be achieved with the datetime module:
from datetime import datetime
time_string = '3h 54m'
datetime_obj = datetime.strptime(time_string, '%Hh %Mm')
total_mins = (datetime_obj.hour * 60) datetime_obj.minute
time_in_hours = total_mins / 60
# Outputs: `3.9 234`
print(time_in_hours, total_mins)
Here '%H' means the number of hours and '%M' is the number of minutes (both zero-padded). If this is encapsulated in a function, it can applied on the data from your spreadsheet that has been read-in via numpy or pandas.
REFERENCE:
https://docs.python.org/3/library/datetime.html#datetime.datetime.strptime
CodePudding user response:
3h 54m is not 3.54. It's 3 54/60 = 3.9. Also since you have some items with seconds, it may be best to do all the conversions to seconds so you don't lose significant digits due to rounding if you need to add any of the items. For example, if you have 37 minutes, that's 0.61666667 hours. So using seconds, you get more precise results if you have to combine things.
The function below can handle h m and s and any combo of them. I provide examples at the bottom. I'm sure there are hundreds of ways to do this conversion. There are tons of examples on StackOverflow of reading and using CSV files so I didn't provide info. I like playing with the math stuff. :)
def hms_to_seconds(time_string):
timeparts = []
# split string. Assumes blank space(s) between each time componet
timeparts = time_string.split()
h = 0
m = 0
s = 0
# loop through the componets and get values
for part in timeparts:
if (part[-1] == "h"):
h = int( part.partition("h")[0] )
if (part[-1] == "m"):
m = int( part.partition("m")[0] )
if (part[-1] == "s"):
s = int( part.partition("s")[0] )
return (h*3600 m*60 s)
print(hms_to_seconds("3h 45m")) # 13500 sec
print(hms_to_seconds("1m 1s")) # 61 sec
print(hms_to_seconds("1h 1s")) # 3601 sec
print(hms_to_seconds("2h")) # 7200 sec
print(hms_to_seconds("10m")) # 600 sec
print(hms_to_seconds("33s")) # 33 sec
CodePudding user response:
1. Read .csv
Reading the csv file into memory can be done using pd.read_csv()
2. Parse time string
Parser
Ideally you want to write a parser that can parse the time string for you. This can be done using ANTLR or by writing one yourself. See e.g. this blog post. This would be the most interesting solution and also the most challenging one. There might be a parser already out there which can handle this as the format is quite common, so you might wanna search for one.
RegEx
A quick and dirty solution however can be implemented using RegEx. The idea is to use this RegEx [0-9]*(?=h) for hours, [0-9]*(?=m) for minutes, [0-9]*(?=s) for seconds to extract the actual values before those identifiers and then calculate the total duration in seconds.
Please note: this is not an ideal solution and only works for "h", "m", "s" and there are edge cases that are not handled in this implementation but it does work in principle.
import re
duration_calcs = {
"h": 60 * 60, # convert hours to seconds => hours * 60 * 60
"m": 60, # convert minutes to seconds => minutes * 60
"s": 1, # convert seconds to seconds => seconds * 1
}
tests_cases = [
"3h 54m",
"4h 9m",
"12s",
"41m 1s"
]
tests_results = [
int(14040), # 3 * 60 * 60 54 * 60
14940, # 4 * 60 * 60 9 * 60
12, # 12 * 1
2461 # 41 * 60 1 * 1
]
def get_duration_component(identifier, text):
"""
Gets one component of the duration from the string and returns the duration in seconds.
:param identifier: either "h", "m" or "s"
:type identifier: str
:param text: text to extract the information from
:type text: str
:return duration in seconds
"""
# RegEx using positive lookahead to either "h", "m" or "s" to extract number before that identifier
regex = re.compile(f"[0-9]*(?={identifier})")
match = regex.search(text)
if not match:
return 0
return int(match.group()) * duration_calcs[identifier]
def get_duration(text):
"""
Get duration from text which contains duration like "4h 43m 12s".
Only "h", "m" and "s" supported.
:param text: text which contains a duration
:type text: str
:return: duration in seconds
"""
idents = ["h", "m", "s"]
total_duration = 0
for ident in idents:
total_duration = get_duration_component(ident, text)
return total_duration
def run_tests(tests, test_results):
"""
Run tests to verify that this quick and dirty implementation works at least for the given test cases.
:param tests: test cases to run
:type tests: list[str]
:param test_results: expected test results
:type test_results: list[int]
:return:
"""
for i, (test_inp, expected_output) in enumerate(zip(tests, test_results)):
result = get_duration(test_inp)
print(f"Test {i}: Input={test_inp}\tExpected Output={expected_output}\tResult: {result}", end="")
if result == expected_output:
print(f"\t[SUCCESS]")
else:
print(f"\t[FAILURE]")
run_tests(tests_cases, tests_results)
Expected result
Test 0: Input=3h 54m Expected Output=14040 Result: 14040 [SUCCESS]
Test 1: Input=4h 9m Expected Output=14940 Result: 14940 [SUCCESS]
Test 2: Input=12s Expected Output=12 Result: 12 [SUCCESS]
Test 3: Input=41m 1s Expected Output=2461 Result: 2461 [SUCCESS]
split()
Another (even simpler) solution could be to split() at space and use some if statements to determine whether a part is "h", "m" or "s" and then parse the preceding string to int and convert is as shown above. The idea is similar, so I did not write a program for this.