I am extracting annual reports pdf file from the website .
import requests
import pandas as pd
from bs4 import BeautifulSoup
url1 = "https://investor.alaskaair.com/financial-information/sec-filings?field_nir_sec_form_group_target_id[]=471&field_nir_sec_date_filed_value=#views-exposed-form-widget-sec-filings-table"
source = requests.get(url1)
soup = BeautifulSoup(source.text , "html.parser")
I am trying to extract columns from the above mentioned URL but in the view column we have only 8 rows thus throws value Error = arrays must all be same length
tag2 = soup.find_all('div' , class_="field field--name-field-nir-sec-form-group field--type-entity-reference field--label-inline field__item")
def filing_group(tag2):
filing_group = []
for i in tag2:
filing_group.append(i.text.strip())
return filing_group
filing_group(tag2)
tag4 = soup.find_all('span' , class_ = "file file--mime-application-pdf file--application-pdf")
def view(tag4):
view = []
try:
for i in tag4:
view.append(i.a.get('href'))
except AttributeError:
view.append(None)
return view
view(tag4)
def scrape_page():
all_info = {}
all_info = {
"Filing Group" : [],
"View" : []
}
all_info["Filing Group"] = filing_group(tag2)
all_info["View"] = view(tag4)
return all_info
scrape_page_df = pd.DataFrame(scrape_page())
CodePudding user response:
As suggested by @hteza, there are missing links so you need to build your data row by row and not column by column:
table = soup.find('table', {'class': 'views-table'})
data = []
for row in table.find('tbody').find_all('tr'):
group = row.find('div', {'class': 'field field--name-field-nir-sec-form-group field--type-entity-reference field--label-inline field__item'}).text
pdf = row.find('span', {'class': 'file file--mime-application-pdf file--application-pdf'})
view = pdf.find('a')['href'] if pdf else None
data.append({'Filling Group': group, 'View': view})
df = pd.DataFrame(data)
Output:
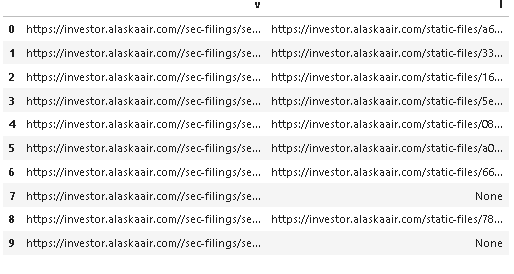
>>> df
Filling Group View
0 Annual Filings https://investor.alaskaair.com/static-files/a686b1d8-6bc5-41ee-9e1a-3860907ed26f
1 Annual Filings https://investor.alaskaair.com/static-files/33d26e56-06c0-44bc-8078-58fbd8103186
2 Annual Filings https://investor.alaskaair.com/static-files/16b87b83-b3bf-4e33-8ef5-148cf48b336b
3 Annual Filings https://investor.alaskaair.com/static-files/5e3082dd-f9fe-493e-9bf9-978c658a13a4
4 Annual Filings https://investor.alaskaair.com/static-files/086708d7-3a13-4683-a381-21eb77634172
5 Annual Filings https://investor.alaskaair.com/static-files/a09bc200-0c2b-478c-8827-d84044c1fcba
6 Annual Filings https://investor.alaskaair.com/static-files/66234ad1-4934-4330-8770-36c4ccebebd0
7 Annual Filings None
8 Annual Filings https://investor.alaskaair.com/static-files/78aa7028-887b-41e8-a173-bf27dccb34b0
9 Annual Filings None
CodePudding user response:
Use:
table = soup.find('table', {'class':"nirtable views-table views-view-table cols-5 collapse-table-wide"})
trs = [x.find_all('td') for x in table.find_all('tr')]
vs = []
ls = []
for tr in trs:
if len(tr)>0:
v = 'https://investor.alaskaair.com/' tr[1].a['href']
print(v)
try:
l = tr[4].find('span', {'class':'file file--mime-application-pdf file--application-pdf'}).a.get('href')
except:
l = None
print(l)
vs.append(v)
ls.append(l)
pd.DataFrame({'v':vs, 'l':ls})
Output: