Suppose I am having a data like this:
Length Width Height
100 140 100
120 150 110
140 160 120
160 170 130
170 190 140
200 200 150
210 210 160
220 220 170
Now, I want to know the distribution of data in each column with a certain increment For example: If I want to see the distribution of data in Length column from 100 to 160 with an increment of 30 and I want to see the output like
Min Max count Percentage Remaining values(out the range which we have given)
100 130 1 12.5 7
130 160 2 25 5
And how to draw the bar graph from it? Please help
CodePudding user response:
You can use pd.cut to achieve your goal:
out = df.groupby(pd.cut(df['Length'], np.arange(100, 160 1, 30)))['Length'] \
.agg(**{'Min': 'min', 'Max': 'max', 'Count': 'count',
'Percentage': lambda x: 100 * x.size / len(df),
'Remaining': lambda x: len(df) - x.size})
print(out)
# Output
Min Max Count Percentage Remaining
Length
(100, 130] 120 120 1 12.5 7
(130, 160] 140 160 2 25.0 6
CodePudding user response:
IIUC, you could use pandas.cut:
(df.groupby(pd.cut(df['Length'], bins=[100,130,160]))
['Length'].agg(count='count')
.assign(**{'Remaining value': lambda d: len(df)-d['count'],
'Percentage': lambda d: d['count']/len(df)*100,
})
)
output:
count Remaining value Percentage
Length
(100, 130] 1 7 12.5
(130, 160] 2 6 25.0
For graphing, you can do it automatically with many libraries.
Example with seaborn:
import seaborn as sns
sns.histplot(df, bins=[100,130,160,190,220])
output:
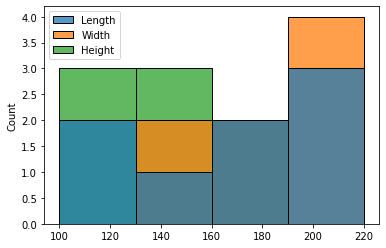
or
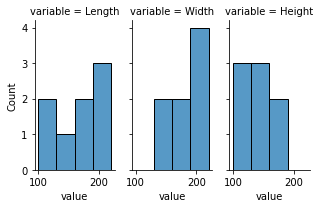
sns.displot(df.melt(), x='value', col='variable',
kind='hist', bins=[100,130,160,190,220])
output: