Below you can see a short example of my table.
library(data.table)
library(dplyr)
Table2<-structure(list(Participant = c("ER", "EA"), Country = c("Belgium",
"Bulgaria"), Y_0_4.Male = c(0, 0), Y_0_4.Female = c(0, 0), Y_5_9.Male = c(0,
3), Y_5_9.Female = c(5, 0), Total = c(5, 3), Data = c(2018, 2018
)), row.names = c(NA, -2L), class = c("data.table", "data.frame"
))

Now I want to do two things with my table.
The first is to separate columns that contain age (e.g Y_0_4 and Y_5_9 ) in separate columns with the title Age, and The second is to separate titles that contain words Female and Male in two separate columns.Below you how it looks like the table.
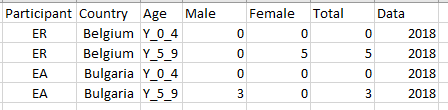
So can anybody help me how to solve this problem ?
CodePudding user response:
You can use pivot_longer from tidyr:
library(tidyr)
library(dplyr)
pivot_longer(Table2, matches('\\.'), names_sep = '\\.', names_to = c('Age', '.value')) %>%
mutate(Total = Male Female)
#> # A tibble: 4 x 7
#> Participant Country Total Data Age Male Female
#> <chr> <chr> <dbl> <dbl> <chr> <dbl> <dbl>
#> 1 ER Belgium 0 2018 Y_0_4 0 0
#> 2 ER Belgium 5 2018 Y_5_9 0 5
#> 3 EA Bulgaria 0 2018 Y_0_4 0 0
#> 4 EA Bulgaria 3 2018 Y_5_9 3 0
CodePudding user response:
You could use melt() from the data.table library:
Reprex
- Code
library(data.table)
melt(Table2,
id.vars = c("Participant", "Country", "Data"),
measure.vars = patterns("\\d\\.M", "\\d\\.F"),
variable.name = "Age",
value.name = c("Male", "Female"))[, `:=` (Age = tstrsplit(grep("\\d\\.[MF]", names(Table2), value = TRUE),"\\.")[[1]], Total = Male Female)][order(Country),][]
- Output
#> Participant Country Data Age Male Female Total
#> 1: ER Belgium 2018 Y_0_4 0 0 0
#> 2: ER Belgium 2018 Y_5_9 0 5 5
#> 3: EA Bulgaria 2018 Y_0_4 0 0 0
#> 4: EA Bulgaria 2018 Y_5_9 3 0 3
Created on 2022-03-14 by the reprex package (v2.0.1)