I have implemented a Convolutional Neural Network in C and have been studying what parts of it have the longest latency.
Based on my research, the massive amounts of matricial multiplication required by CNNs makes running them on CPUs and even GPUs very inefficient. However, when I actually profiled my code (on an unoptimized build) I found out that something other than the multiplication itself was the bottleneck of the implementation.
After turning on optimization (-O3 -march=native -ffast-math, gcc cross compiler), the Gprof result was the following:
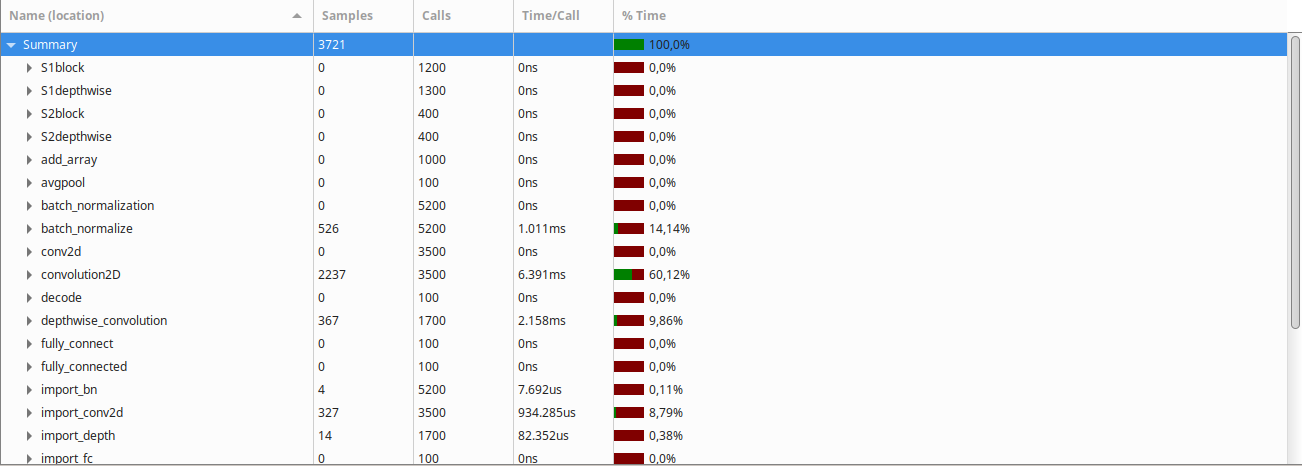
Clearly, the convolution2D function takes the largest amount of time to run, followed by the batch normalization and depthwise convolution functions.
The convolution function in question looks like this:
void convolution2D(int isize, // width/height of input
int osize, // width/height of output
int ksize, // width/height of kernel
int stride, // shift between input pixels, between consecutive outputs
int pad, // offset between (0,0) pixels between input and output
int idepth, int odepth, // number of input and output channels
float idata[isize][isize][idepth],
float odata[osize][osize][odepth],
float kdata[odepth][ksize][ksize][idepth])
{
// iterate over the output
for (int oy = 0; oy < osize; oy) {
for (int ox = 0; ox < osize; ox) {
for (int od = 0; od < odepth; od) {
odata[oy][ox][od] = 0; // When you iterate multiple times without closing the program, this number would stack up to infinity, so we have to zero it out every time.
for (int ky = 0; ky < ksize; ky) {
for (int kx = 0; kx < ksize; kx) {
// map position in output and kernel to the input
int iy = stride * oy ky - pad;
int ix = stride * ox kx - pad;
// use only valid inputs
if (iy >= 0 && iy < isize && ix >= 0 && ix < isize)
for (int id = 0; id < idepth; id)
odata[oy][ox][od] = kdata[od][ky][kx][id] * idata[iy][ix][id];
}}
}}}
}
This is a design based on my previous question and most of the processing time should fall on the convolution itself: odata[oy][ox][od] = kdata[od][ky][kx][id] * idata[iy][ix][id];.
Using objdump -drwC -Mintel to take a look at the assembly code returns me the following:
0000000000007880 <convolution2D>:
7880: f3 0f 1e fa endbr64
7884: 55 push rbp
7885: 48 89 e5 mov rbp,rsp
7888: 41 57 push r15
788a: 41 56 push r14
788c: 41 55 push r13
788e: 41 54 push r12
7890: 53 push rbx
7891: 48 81 ec b0 00 00 00 sub rsp,0xb0
7898: ff 15 4a a7 00 00 call QWORD PTR [rip 0xa74a] # 11fe8 <mcount@GLIBC_2.2.5>
789e: 89 d3 mov ebx,edx
78a0: 89 55 a8 mov DWORD PTR [rbp-0x58],edx
78a3: 89 8d 74 ff ff ff mov DWORD PTR [rbp-0x8c],ecx
78a9: 49 63 d1 movsxd rdx,r9d
78ac: 48 63 cf movsxd rcx,edi
78af: 41 89 f2 mov r10d,esi
78b2: 89 b5 38 ff ff ff mov DWORD PTR [rbp-0xc8],esi
78b8: 49 63 c0 movsxd rax,r8d
78bb: 48 0f af ca imul rcx,rdx
78bf: 48 63 75 10 movsxd rsi,DWORD PTR [rbp 0x10]
78c3: 49 89 d6 mov r14,rdx
78c6: 4c 8d 24 95 00 00 00 00 lea r12,[rdx*4 0x0]
78ce: 41 89 fd mov r13d,edi
78d1: 49 89 cb mov r11,rcx
78d4: 48 89 8d 60 ff ff ff mov QWORD PTR [rbp-0xa0],rcx
78db: 49 63 ca movsxd rcx,r10d
78de: 4c 8d 0c b5 00 00 00 00 lea r9,[rsi*4 0x0]
78e6: 49 89 f0 mov r8,rsi
78e9: 48 0f af f1 imul rsi,rcx
78ed: 48 63 cb movsxd rcx,ebx
78f0: 4c 89 8d 48 ff ff ff mov QWORD PTR [rbp-0xb8],r9
78f7: 48 0f af d1 imul rdx,rcx
78fb: 48 8d 3c 95 00 00 00 00 lea rdi,[rdx*4 0x0]
7903: 45 85 d2 test r10d,r10d
7906: 0f 8e 73 02 00 00 jle 7b7f <convolution2D 0x2ff>
790c: 48 c1 ef 02 shr rdi,0x2
7910: 49 c1 e9 02 shr r9,0x2
7914: 48 89 7d c8 mov QWORD PTR [rbp-0x38],rdi
7918: 4c 89 e7 mov rdi,r12
791b: 4c 89 8d 58 ff ff ff mov QWORD PTR [rbp-0xa8],r9
7922: 48 c1 ef 02 shr rdi,0x2
7926: 48 89 bd 50 ff ff ff mov QWORD PTR [rbp-0xb0],rdi
792d: 45 85 c0 test r8d,r8d
7930: 0f 8e 49 02 00 00 jle 7b7f <convolution2D 0x2ff>
7936: 48 c1 e6 02 shl rsi,0x2
793a: 48 0f af d1 imul rdx,rcx
793e: 29 c3 sub ebx,eax
7940: 89 c7 mov edi,eax
7942: 48 89 b5 30 ff ff ff mov QWORD PTR [rbp-0xd0],rsi
7949: 48 8b 75 20 mov rsi,QWORD PTR [rbp 0x20]
794d: 48 89 85 68 ff ff ff mov QWORD PTR [rbp-0x98],rax
7954: f7 df neg edi
7956: 45 8d 7e ff lea r15d,[r14-0x1]
795a: 89 9d 70 ff ff ff mov DWORD PTR [rbp-0x90],ebx
7960: 89 bd 3c ff ff ff mov DWORD PTR [rbp-0xc4],edi
7966: 48 8d 0c 95 00 00 00 00 lea rcx,[rdx*4 0x0]
796e: 89 7d ac mov DWORD PTR [rbp-0x54],edi
7971: 89 5d d4 mov DWORD PTR [rbp-0x2c],ebx
7974: 48 89 4d 98 mov QWORD PTR [rbp-0x68],rcx
7978: 4a 8d 0c 9d 00 00 00 00 lea rcx,[r11*4 0x0]
7980: c7 45 80 00 00 00 00 mov DWORD PTR [rbp-0x80],0x0
7987: 48 89 75 88 mov QWORD PTR [rbp-0x78],rsi
798b: 41 8d 70 ff lea esi,[r8-0x1]
798f: 48 89 4d c0 mov QWORD PTR [rbp-0x40],rcx
7993: 48 8d 04 b5 04 00 00 00 lea rax,[rsi*4 0x4]
799b: c7 45 90 00 00 00 00 mov DWORD PTR [rbp-0x70],0x0
79a2: 48 89 85 28 ff ff ff mov QWORD PTR [rbp-0xd8],rax
79a9: 44 89 f0 mov eax,r14d
79ac: 45 89 ee mov r14d,r13d
79af: 41 89 c5 mov r13d,eax
79b2: 48 8b 85 28 ff ff ff mov rax,QWORD PTR [rbp-0xd8]
79b9: 48 03 45 88 add rax,QWORD PTR [rbp-0x78]
79bd: 48 c7 85 78 ff ff ff 00 00 00 00 mov QWORD PTR [rbp-0x88],0x0
79c8: c7 45 84 00 00 00 00 mov DWORD PTR [rbp-0x7c],0x0
79cf: c7 45 94 00 00 00 00 mov DWORD PTR [rbp-0x6c],0x0
79d6: 44 8b 95 70 ff ff ff mov r10d,DWORD PTR [rbp-0x90]
79dd: 48 89 45 b0 mov QWORD PTR [rbp-0x50],rax
79e1: 48 63 45 80 movsxd rax,DWORD PTR [rbp-0x80]
79e5: 48 2b 85 68 ff ff ff sub rax,QWORD PTR [rbp-0x98]
79ec: 48 0f af 85 60 ff ff ff imul rax,QWORD PTR [rbp-0xa0]
79f4: 48 89 85 40 ff ff ff mov QWORD PTR [rbp-0xc0],rax
79fb: 8b 85 3c ff ff ff mov eax,DWORD PTR [rbp-0xc4]
7a01: 89 45 d0 mov DWORD PTR [rbp-0x30],eax
7a04: 48 8b 45 88 mov rax,QWORD PTR [rbp-0x78]
7a08: 48 8b 9d 78 ff ff ff mov rbx,QWORD PTR [rbp-0x88]
7a0f: 4c 8d 04 98 lea r8,[rax rbx*4]
7a13: 48 8b 45 28 mov rax,QWORD PTR [rbp 0x28]
7a17: 48 8b 5d 18 mov rbx,QWORD PTR [rbp 0x18]
7a1b: 48 89 45 b8 mov QWORD PTR [rbp-0x48],rax
7a1f: 48 63 45 84 movsxd rax,DWORD PTR [rbp-0x7c]
7a23: 48 2b 85 68 ff ff ff sub rax,QWORD PTR [rbp-0x98]
7a2a: 48 0f af 85 50 ff ff ff imul rax,QWORD PTR [rbp-0xb0]
7a32: 48 03 85 40 ff ff ff add rax,QWORD PTR [rbp-0xc0]
7a39: 48 8d 04 83 lea rax,[rbx rax*4]
7a3d: 48 89 45 a0 mov QWORD PTR [rbp-0x60],rax
7a41: 66 66 2e 0f 1f 84 00 00 00 00 00 data16 nop WORD PTR cs:[rax rax*1 0x0]
7a4c: 0f 1f 40 00 nop DWORD PTR [rax 0x0]
7a50: 8b 45 a8 mov eax,DWORD PTR [rbp-0x58]
7a53: 41 c7 00 00 00 00 00 mov DWORD PTR [r8],0x0
7a5a: 45 31 db xor r11d,r11d
7a5d: 48 8b 5d a0 mov rbx,QWORD PTR [rbp-0x60]
7a61: 44 8b 4d ac mov r9d,DWORD PTR [rbp-0x54]
7a65: 85 c0 test eax,eax
7a67: 0f 8e 98 00 00 00 jle 7b05 <convolution2D 0x285>
7a6d: 0f 1f 00 nop DWORD PTR [rax]
7a70: 45 85 c9 test r9d,r9d
7a73: 78 7b js 7af0 <convolution2D 0x270>
7a75: 45 39 ce cmp r14d,r9d
7a78: 7e 76 jle 7af0 <convolution2D 0x270>
7a7a: 48 8b 45 b8 mov rax,QWORD PTR [rbp-0x48]
7a7e: 8b 55 d0 mov edx,DWORD PTR [rbp-0x30]
7a81: 48 89 de mov rsi,rbx
7a84: 4a 8d 3c 98 lea rdi,[rax r11*4]
7a88: eb 13 jmp 7a9d <convolution2D 0x21d>
7a8a: 66 0f 1f 44 00 00 nop WORD PTR [rax rax*1 0x0]
7a90: ff c2 inc edx
7a92: 4c 01 e7 add rdi,r12
7a95: 4c 01 e6 add rsi,r12
7a98: 44 39 d2 cmp edx,r10d
7a9b: 74 53 je 7af0 <convolution2D 0x270>
7a9d: 85 d2 test edx,edx
7a9f: 78 ef js 7a90 <convolution2D 0x210>
7aa1: 41 39 d6 cmp r14d,edx
7aa4: 7e ea jle 7a90 <convolution2D 0x210>
7aa6: 45 85 ed test r13d,r13d
7aa9: 7e e5 jle 7a90 <convolution2D 0x210>
7aab: c4 c1 7a 10 08 vmovss xmm1,DWORD PTR [r8]
7ab0: 31 c0 xor eax,eax
7ab2: 66 66 2e 0f 1f 84 00 00 00 00 00 data16 nop WORD PTR cs:[rax rax*1 0x0]
7abd: 0f 1f 00 nop DWORD PTR [rax]
7ac0: c5 fa 10 04 87 vmovss xmm0,DWORD PTR [rdi rax*4]
7ac5: 48 89 c1 mov rcx,rax
7ac8: c5 fa 59 04 86 vmulss xmm0,xmm0,DWORD PTR [rsi rax*4]
7acd: 48 ff c0 inc rax
7ad0: c5 f2 58 c8 vaddss xmm1,xmm1,xmm0
7ad4: c4 c1 7a 11 08 vmovss DWORD PTR [r8],xmm1
7ad9: 49 39 cf cmp r15,rcx
7adc: 75 e2 jne 7ac0 <convolution2D 0x240>
7ade: ff c2 inc edx
7ae0: 4c 01 e7 add rdi,r12
7ae3: 4c 01 e6 add rsi,r12
7ae6: 44 39 d2 cmp edx,r10d
7ae9: 75 b2 jne 7a9d <convolution2D 0x21d>
7aeb: 0f 1f 44 00 00 nop DWORD PTR [rax rax*1 0x0]
7af0: 4c 03 5d c8 add r11,QWORD PTR [rbp-0x38]
7af4: 48 03 5d c0 add rbx,QWORD PTR [rbp-0x40]
7af8: 41 ff c1 inc r9d
7afb: 44 3b 4d d4 cmp r9d,DWORD PTR [rbp-0x2c]
7aff: 0f 85 6b ff ff ff jne 7a70 <convolution2D 0x1f0>
7b05: 48 8b 5d 98 mov rbx,QWORD PTR [rbp-0x68]
7b09: 49 83 c0 04 add r8,0x4
7b0d: 48 01 5d b8 add QWORD PTR [rbp-0x48],rbx
7b11: 4c 3b 45 b0 cmp r8,QWORD PTR [rbp-0x50]
7b15: 0f 85 35 ff ff ff jne 7a50 <convolution2D 0x1d0>
7b1b: 8b 9d 74 ff ff ff mov ebx,DWORD PTR [rbp-0x8c]
7b21: 8b 45 94 mov eax,DWORD PTR [rbp-0x6c]
7b24: 48 8b 8d 48 ff ff ff mov rcx,QWORD PTR [rbp-0xb8]
7b2b: 01 5d d0 add DWORD PTR [rbp-0x30],ebx
7b2e: 48 01 4d b0 add QWORD PTR [rbp-0x50],rcx
7b32: 01 5d 84 add DWORD PTR [rbp-0x7c],ebx
7b35: 48 8b 8d 58 ff ff ff mov rcx,QWORD PTR [rbp-0xa8]
7b3c: 41 01 da add r10d,ebx
7b3f: 48 01 8d 78 ff ff ff add QWORD PTR [rbp-0x88],rcx
7b46: ff c0 inc eax
7b48: 39 85 38 ff ff ff cmp DWORD PTR [rbp-0xc8],eax
7b4e: 74 08 je 7b58 <convolution2D 0x2d8>
7b50: 89 45 94 mov DWORD PTR [rbp-0x6c],eax
7b53: e9 ac fe ff ff jmp 7a04 <convolution2D 0x184>
7b58: 8b 4d 90 mov ecx,DWORD PTR [rbp-0x70]
7b5b: 48 8b b5 30 ff ff ff mov rsi,QWORD PTR [rbp-0xd0]
7b62: 01 5d d4 add DWORD PTR [rbp-0x2c],ebx
7b65: 01 5d ac add DWORD PTR [rbp-0x54],ebx
7b68: 01 5d 80 add DWORD PTR [rbp-0x80],ebx
7b6b: 48 01 75 88 add QWORD PTR [rbp-0x78],rsi
7b6f: 8d 41 01 lea eax,[rcx 0x1]
7b72: 39 4d 94 cmp DWORD PTR [rbp-0x6c],ecx
7b75: 74 08 je 7b7f <convolution2D 0x2ff>
7b77: 89 45 90 mov DWORD PTR [rbp-0x70],eax
7b7a: e9 33 fe ff ff jmp 79b2 <convolution2D 0x132>
7b7f: 48 81 c4 b0 00 00 00 add rsp,0xb0
7b86: 5b pop rbx
7b87: 41 5c pop r12
7b89: 41 5d pop r13
7b8b: 41 5e pop r14
7b8d: 41 5f pop r15
7b8f: 5d pop rbp
7b90: c3 ret
7b91: 66 66 2e 0f 1f 84 00 00 00 00 00 data16 nop WORD PTR cs:[rax rax*1 0x0]
7b9c: 0f 1f 40 00 nop DWORD PTR [rax 0x0]
For reference, I'm using an AMD Ryzen 7 CPU which uses Zen2 architecture. Here is its list of instructions (page 101).
I suspect that the data here points to a memory issue instead of simply the multiplication being the cause of the bottleneck.
Question:
How can I improve this code so that it does not cause a memory bottleneck?
I'm guessing this is actually a problem particular to my code, perhaps something related to the multidimensional arrays I'm using. If I instead used one big single-dimentional array for each variable, would the latency decrease?
Relevant information:
There are two ways I declare the variables that are passed to this function. The first is as a global variable (usually in a struct), the second is as dynamic allocation:
float (*arr)[x][y] = calloc(z, sizeof *arr);
Perhaps the order in which I declare these matrixes is not cache-friendly, but I am not sure how to re-order it.
Stride values for the previous function are always 1 or 2, usually 1.
Here is the output of valgrind --tool=cachegrind:
==430300== Cachegrind, a cache and branch-prediction profiler
==430300== Copyright (C) 2002-2017, and GNU GPL'd, by Nicholas Nethercote et al.
==430300== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
==430300== Command: ./EmbeddedNet test 1
==430300== Parent PID: 170008
==430300==
--430300-- warning: L3 cache found, using its data for the LL simulation.
==430300==
==430300== I refs: 6,369,594,192
==430300== I1 misses: 4,271
==430300== LLi misses: 2,442
==430300== I1 miss rate: 0.00%
==430300== LLi miss rate: 0.00%
==430300==
==430300== D refs: 2,064,233,110 (1,359,003,131 rd 705,229,979 wr)
==430300== D1 misses: 34,476,969 ( 19,010,839 rd 15,466,130 wr)
==430300== LLd misses: 5,311,277 ( 1,603,955 rd 3,707,322 wr)
==430300== D1 miss rate: 1.7% ( 1.4% 2.2% )
==430300== LLd miss rate: 0.3% ( 0.1% 0.5% )
==430300==
==430300== LL refs: 34,481,240 ( 19,015,110 rd 15,466,130 wr)
==430300== LL misses: 5,313,719 ( 1,606,397 rd 3,707,322 wr)
==430300== LL miss rate: 0.1% ( 0.0% 0.5% )
CodePudding user response:
Looking at the result of Cachegrind, it doesn't look like the memory is your bottleneck. The NN has to be stored in memory anyway, but if it's too large that your program's having a lot of L1 cache misses, then it's worth thinking to try to minimize L1 misses, but 1.7% of L1 (data) miss rate is not a problem.
So you're trying to make this run fast anyway. Looking at your code, what's happening at the most inner loop is very simple (load-> multiply -> add -> store), and it doesn't have any side effect other than the final store. This kind of code is easily parallelizable, for example, by multithreading or vectorizing. I think you'll know how to make this run in multiple threads seeing that you can write code with some complexity, and you asked in comments how to manually vectorize the code.
I will explain that part, but one thing to bear in mind is that once you choose to manually vectorize the code, it will often be tied to certain CPU architectures. Let's not consider non-AMD64 compatible CPUs like ARM. Still, you have the option of MMX, SSE, AVX, and AVX512 to choose as an extension for vectorized computation, and each extension has multiple versions. If you want maximum portability, SSE2 is a reasonable choice. SSE2 appeared with Pentium 4, and it supports 128-bit vectors. For this post I'll use AVX2, which supports 128-bit and 256-bit vectors. It runs fine on your CPU, and has reasonable portability these days, supported from Haswell (2013) and Excavator (2015).
The pattern you're using in the inner loop is called FMA (fused multiply and add). AVX2 has an instruction for this. Have a look at this function and the compiled output.
float fma_scl(float a, float b, float c) {
return a * b c;
}
fma_scl:
vfmadd132ss xmm0, xmm2, xmm1
ret
You can see the calculation done with a single instruction.
We'll define a 256-bit vector type using GCC's vector extension.
typedef float Vec __attribute__((vector_size(32), aligned(32)));
Here's a vectorized fma function.
Vec fma_vec(Vec a, Vec b, Vec c) {
return a * b c;
}
fma_vec:
vfmadd132ps ymm0, ymm2, ymm1
ret
The code above is semantically the same as the one below, but everything is done in a single instruction.
typedef struct {
float f[8];
} Vec_;
Vec_ fma_vec_(Vec_ a, Vec_ b, Vec_ c) {
Vec_ r;
for (unsigned i = 0; i < 8; i) {
r.f[i] = a.f[i] * b.f[i] c.f[i];
}
return r;
}
I think you'll now get the idea of making code run faster by vectorization.
Here is a simple function that's somewhat similar to your inner loop.
void loopadd_scl(float *restrict a, float *restrict b, float *restrict c, unsigned n) {
for (unsigned i = 0; i < n; i) {
a[i] = fma_scl(b[i], c[i], a[i]);
}
}
When you compile through GCC with -O3 -march=znver2, this is the output. It's huge. I'll explain below.
loopadd_scl:
test ecx, ecx
je .L25
lea eax, [rcx-1]
cmp eax, 6
jbe .L13
mov r8d, ecx
xor eax, eax
shr r8d, 3
sal r8, 5
.L9:
vmovups ymm1, YMMWORD PTR [rdi rax]
vmovups ymm0, YMMWORD PTR [rdx rax]
vfmadd132ps ymm0, ymm1, YMMWORD PTR [rsi rax]
vmovups YMMWORD PTR [rdi rax], ymm0
add rax, 32
cmp r8, rax
jne .L9
mov eax, ecx
and eax, -8
test cl, 7
je .L26
vzeroupper
.L8:
mov r9d, ecx
sub r9d, eax
lea r8d, [r9-1]
cmp r8d, 2
jbe .L11
mov r8d, eax
sal r8, 2
lea r10, [rdi r8]
vmovups xmm0, XMMWORD PTR [rdx r8]
vmovups xmm2, XMMWORD PTR [r10]
vfmadd132ps xmm0, xmm2, XMMWORD PTR [rsi r8]
mov r8d, r9d
and r8d, -4
add eax, r8d
and r9d, 3
vmovups XMMWORD PTR [r10], xmm0
je .L25
.L11:
mov r8d, eax
sal r8, 2
lea r9, [rdi r8]
vmovss xmm0, DWORD PTR [rdx r8]
vmovss xmm3, DWORD PTR [r9]
vfmadd132ss xmm0, xmm3, DWORD PTR [rsi r8]
lea r8d, [rax 1]
vmovss DWORD PTR [r9], xmm0
cmp r8d, ecx
jnb .L25
sal r8, 2
add eax, 2
lea r9, [rdi r8]
vmovss xmm0, DWORD PTR [rsi r8]
vmovss xmm4, DWORD PTR [r9]
vfmadd132ss xmm0, xmm4, DWORD PTR [rdx r8]
vmovss DWORD PTR [r9], xmm0
cmp eax, ecx
jnb .L25
sal rax, 2
add rdi, rax
vmovss xmm0, DWORD PTR [rdx rax]
vmovss xmm5, DWORD PTR [rdi]
vfmadd132ss xmm0, xmm5, DWORD PTR [rsi rax]
vmovss DWORD PTR [rdi], xmm0
.L25:
ret
.L26:
vzeroupper
ret
.L13:
xor eax, eax
jmp .L8
Basically GCC doesn't know anything about n, so it's splitting the loop to 3 cases: n / 8 > 1, n / 4 > 1, n < 4. It first deals with the n / 8 > 1 part using 256-bit ymm registers. Then, it deals with n / 4 > 1 with 128-bit xmm registers. Finally, it deals with n < 4 with scalar ss instructions.
You can avoid this mess if you know n is a multiple of 8. I got a bit lazy now, so have a look at the code and the compiler output below and compare it with the above. I think you're smart enough to get the idea.
void loopadd_vec(Vec *restrict a, Vec *restrict b, Vec *restrict c, unsigned n) {
n /= 8;
for (unsigned i = 0; i < n; i) {
a[i] = fma_vec(b[i], c[i], a[i]);
}
}
loopadd_vec:
shr ecx, 3
je .L34
mov ecx, ecx
xor eax, eax
sal rcx, 5
.L29:
vmovaps ymm1, YMMWORD PTR [rdi rax]
vmovaps ymm0, YMMWORD PTR [rdx rax]
vfmadd132ps ymm0, ymm1, YMMWORD PTR [rsi rax]
vmovaps YMMWORD PTR [rdi rax], ymm0
add rax, 32
cmp rcx, rax
jne .L29
vzeroupper
.L34:
ret
}