I have a very trivial problem but I don't know well the Pandas library and I don't know how to operate.
I have a dataframe where there is the Id of the subjects, and some metrics (A, B, C) repeated for the number of stimuli (Stim_1, Stim_2, etc..)
I need to create from this dataframe another dataframe composed of the averages of each stimulus for the individual metrics. Till now i wrote
df_mean = pd.DataFrame()
for col in df:
m = df[col].mean()
Here the original dataframe
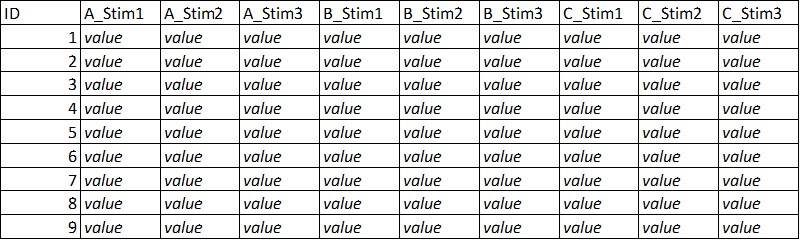
and
here the dataframe I want to create
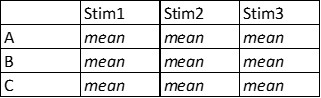
CodePudding user response:
You can create MultiIndex by all columns without ID by split, so possible reshape by DataFrame.stack with aggregate mean by second level:
print (df)
ID A_Stim1 A_Stim2 A_Stim3 B_Stim1 B_Stim2 B_Stim3
0 1 1 5 6 9 8 7
1 8 1 6 4 5 4 5
df1 = df.set_index('ID')
df1.columns = df1.columns.str.split('_', expand=True, n=1)
df2 = df1.stack(0).groupby(level=1).mean()
print (df2)
Stim1 Stim2 Stim3
A 1.0 5.5 5.0
B 7.0 6.0 6.0
CodePudding user response:
You can use pandas.wide_to_long:
cols = ['A', 'B', 'C']
# or generic
cols = df.columns.str.extract('([^_] )_', expand=False).unique()
(pd
.wide_to_long(df.reset_index(), cols,
i='index', j='id2', sep='_',
suffix='Stim\d ') # can also be generic '. '
.groupby(level='id2').mean()
.T
)
output (input of same shape as provided, filled with 1s):
id2 Stim1 Stim2 Stim3
A 1.0 1.0 1.0
B 1.0 1.0 1.0
C 1.0 1.0 1.0