i have given txt file in following format
a: 40 b: 20 c: 20 d: 00 23 4f 40 5f
a: 20 b: 30 c: 50 d: 23 45 21 54 43
a: 20 b: 30 c: 50 d: 23 45 21
a: 20 b: 30 c: 50 d:
i used read_csv() function to read the fiven file. However i am struggling with make this type of format as dataframe in order to analyze.
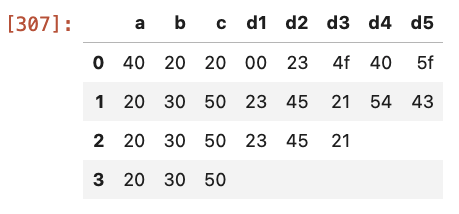
the final dataframe i want is
a b c d_1 d_2 d_3 d_4 d_5
40 20 20 00 23 4f 40 5f
20 30 50 23 45 21 54 43
20 30 50 23 45 21
20 30 50
I Have tried split function using ' ' as divisor. However since there is data that are not written it causes disorder.
Is there another way to make this type of data as data frame.
CodePudding user response:
It may be hard if you try to find a way to load it with read_csv(). I think it would be better if you clean your data before loading it into a data frame.
def check_index(list, index):
return "" if index > (len(list)-1) else list[index].rstrip()
a, b, c, d1 ,d2, d3, d4, d5 = [] , [] ,[] , [],[] , [] ,[] , []
with open('./text.txt') as file:
for line in file.readlines():
values = list(compo.split(': ')[1] for compo in line.split(' ')) # 4 space split according to your sample data
a.append(values[0])
b.append(values[1])
c.append(values[2])
d_values = values[3].split(' ')
d1.append(check_index(d_values,0))
d2.append(check_index(d_values,1))
d3.append(check_index(d_values,2))
d4.append(check_index(d_values,3))
d5.append(check_index(d_values,4))
df = pd.DataFrame(list(zip(a, b, c, d1 ,d2, d3, d4, d5)), columns = ['a', 'b', 'c', 'd1', 'd2', 'd3', 'd4', 'd5'])
CodePudding user response:
start with:
s = """a: 40 b: 20 c: 20 d: 00 23 4f 40 5f
a: 20 b: 30 c: 50 d: 23 45 21 54 43
a: 20 b: 30 c: 50 d: 23 45 21
a: 20 b: 30 c: 50 d: """
Split into rows:
rows = s.split("\n")
rows
['a: 40 b: 20 c: 20 d: 00 23 4f 40 5f', 'a: 20 b: 30 c: 50 d: 23 45 21 54 43', 'a: 20 b: 30 c: 50 d: 23 45 21 ', 'a: 20 b: 30 c: 50 d: ']
Split row into columns:
cols = row.split(" ")
cols
['a: 40', ' b: 20', 'c: 20', ' d: 00 23 4f 40 5f']
Split a cell into the column letter and values:
cell = cols[-1]
letter, values = cell.split(":")
letter
' d'
values
' 00 23 4f 40 5f'
convert letter and values into a dictionary:
new_col = {f"{letter}_{i}": v for i, v in enumerate(values.strip(" ").split(" "))}
new_col
{' d_0': '00', ' d_1': '23', ' d_2': '4f', ' d_3': '40', ' d_4': '5f'}
Merge the dictionaries back together:
def merge_dicts(list_of_dicts: List[Dict[str, str]]):
new_d = {}
for d in list_of_dicts:
new_d.update(d)
return new_d
rows = [merge_dicts(row) for row in cells]
rows
[{'a_0': '40', 'b_0': '20', 'c_0': '20', 'd_0': '00', 'd_1': '23', 'd_2': '4f', 'd_3': '40', 'd_4': '5f'}, {'a_0': '20', 'b_0': '30', 'c_0': '50', 'd_0': '23', 'd_1': '45', 'd_2': '21', 'd_3': '54', 'd_4': '43'}, {'a_0': '20', 'b_0': '30', 'c_0': '50', 'd_0': '23', 'd_1': '45', 'd_2': '21'}, {'a_0': '20', 'b_0': '30', 'c_0': '50', 'd_0': ''}]
Convert to a dataframe:
df = pd.DataFrame(rows)
a_0 b_0 c_0 d_0 d_1 d_2 d_3 d_4
0 40 20 20 00 23 4f 40 5f
1 20 30 50 23 45 21 54 43
2 20 30 50 23 45 21 NaN NaN
3 20 30 50 NaN NaN NaN NaN
full code:
from typing import List, Dict
import pandas as pd
s = """a: 40 b: 20 c: 20 d: 00 23 4f 40 5f
a: 20 b: 30 c: 50 d: 23 45 21 54 43
a: 20 b: 30 c: 50 d: 23 45 21
a: 20 b: 30 c: 50 d: """
def cell_to_dict(cell: str):
letter, values = cell.split(":")
letter = letter.strip(" ")
values = values.strip(" ")
d = {f"{letter}_{i}": v for i, v in enumerate(values.split(" "))}
return d
def merge_dicts(list_of_dicts: List[Dict[str, str]]):
new_d = {}
for d in list_of_dicts:
new_d.update(d)
return new_d
def parse_file(s: str):
rows = s.split("\n")
cols = [row.split(" ") for row in rows]
cells = [[cell_to_dict(cell) for cell in col] for col in cols]
rows = [merge_dicts(row) for row in cells]
df = pd.DataFrame(rows)
return df
print(parse_file(s))
Its not quite there as cell ["d_0"][3] is '' rather than NaN, and the names of the columns are slightly different, but its pretty close
CodePudding user response:
You need to create a new list of your columns in the desired order, then use df = df[cols] to rearrange the columns in this new order.