Looking to conditionally merge a summary dataframe that was value_count -ed:
traitcount_df = traits_df['Trait_Count'].value_counts(normalize=True, dropna=False, ascending=True).to_frame()
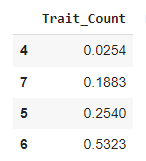
to the main dataframe:
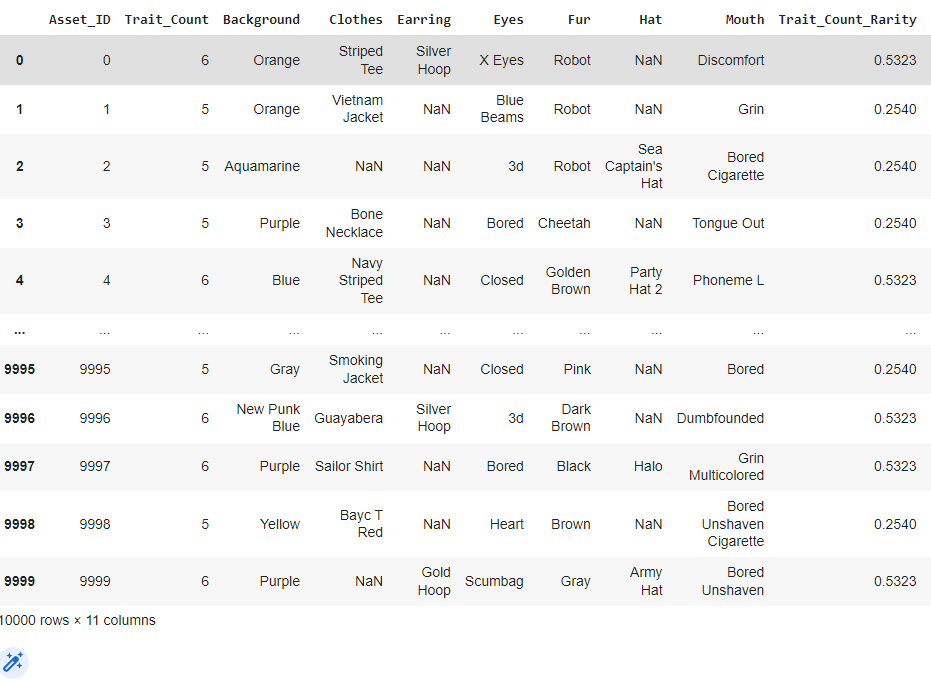
I used this code originally but would like to be able to do it with the summary dataframe, first column acting as the key and conditionally loading.
rarity_conditions = [
(traits_df['Trait_Count'] == 4),
(traits_df['Trait_Count'] == 5),
(traits_df['Trait_Count'] == 6),
(traits_df['Trait_Count'] == 7)
]
rarity_values = [.0254, .2540, .5323, .1883]
traits_df['Trait_Count_Rarity'] = np.select(rarity_conditions, rarity_values)
Ive tried it with other dataframes unsuccessfully:
mouth_conditions = [
(traits_df['Mouth'] = mouth_df[])
mouth_values = mouth_df['Mouth']
traits_df['Mouth_Rarity'] = np.select(mouth_conditions, mouth_values)
CodePudding user response:
You can a lot simplify your solution:
s = traits_df['Trait_Count'].value_counts(normalize=True, dropna=False, ascending=True)
traits_df = traits_df.join(s.rename('Trait_Count_Rarity'), on='Trait_Count')
instead:
traitcount_df = traits_df['Trait_Count'].value_counts(normalize=True, dropna=False, ascending=True).to_frame()
rarity_conditions = [
(traits_df['Trait_Count'] == 4),
(traits_df['Trait_Count'] == 5),
(traits_df['Trait_Count'] == 6),
(traits_df['Trait_Count'] == 7)
]
rarity_values = [.0254, .2540, .5323, .1883]
traits_df['Trait_Count_Rarity'] = np.select(rarity_conditions, rarity_values)