I created a data frame with spacy (columns: sentencens, tokens, stopwords, content words, pos, entities) and saved it as a csv. When I read it as a csv file (it looks pretty decent), but when I perform a for loop over the columns, it does not return the expected result (for my basic domain of Python).
For example:
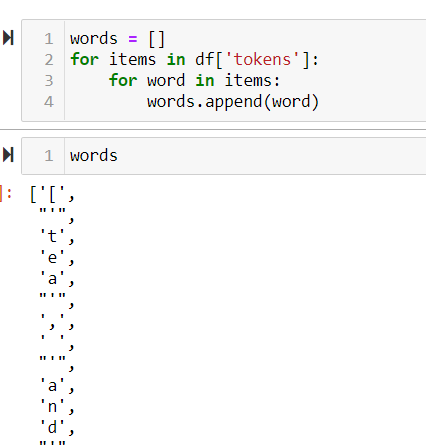
words = []
for items in df['tokens']:
for word in items:
words.append(word)
what I expected [tea, and, ...]
what I got ['t', 'e', 'a', ',', ' ', 'a', 'n', 'd', . . .
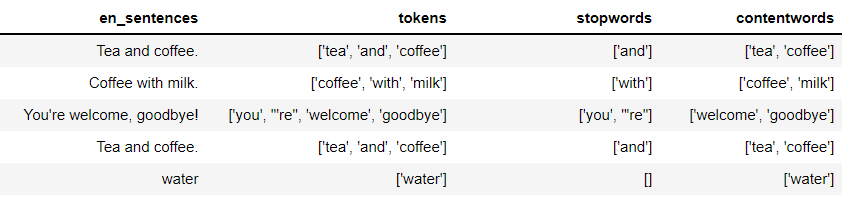 It happens in any column I try to iterate over. What is wrong with it?
I need it to be a csv as it is, to be shared with college mates that uses excel to visualize the data.
It happens in any column I try to iterate over. What is wrong with it?
I need it to be a csv as it is, to be shared with college mates that uses excel to visualize the data.
CodePudding user response:
from ast import literal_eval
df = pd.read_csv('sample.csv', converters={'tokens': literal_eval})
print(df.iloc[0,0][0])
This should help you evaluate the list of strings and then parse it out separately as needed. Then your for loop will work as above
CodePudding user response:
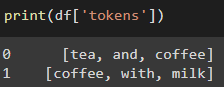
I didn't had the minimum reproducible example. I created one:
import pandas as pd
df = pd.DataFrame(
{ 'tokens': [['tea','and','coffee'],['coffee','with','milk']]})
words = []
for items in df['tokens']:
for word in items:
words.append(word)

Please show us your df['tokens'] and give us a minimum reproducible example, I will edit accordingly.