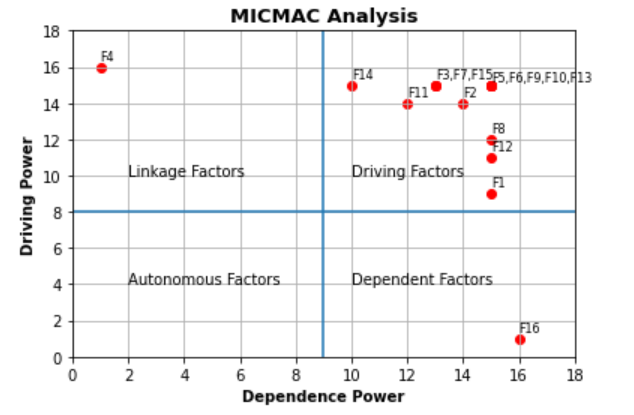
My Dataframe looks like this:
Driving Power Dependence Power
F1 9.0 15.0
F2 14.0 14.0
F3 15.0 13.0
F4 16.0 1.0
F5 15.0 15.0
F6 15.0 15.0
F7 15.0 13.0
F8 12.0 15.0
F9 15.0 15.0
F10 15.0 15.0
F11 14.0 12.0
F12 11.0 15.0
F13 15.0 15.0
F14 15.0 10.0
F15 15.0 13.0
F16 1.0 16.0
I plotted above data using the following code:
#data Frame for x, y
x = prom['Dependence Power']
y = prom['Driving Power']
n = ['F1','F2','F3','F4','F5','F6','F7','F8','F9','F10','F11','F12','F13','F14','F15','F16']
##########################################
plt.scatter(x, y, color="red")
plt.xlim([0, 18])
plt.ylim([0, 18])
for i, txt in enumerate(n):
plt.annotate(txt, (x[i], y[i]), fontsize=8, rotation=0)
plt.ylabel('Driving Power', fontweight='bold')
plt.xlabel('Dependence Power', fontweight='bold')
plt.title("MICMAC Analysis", fontsize = 13,fontweight='bold')
plt.grid()
#axis lines
plt.axhline(y=8, xmin=0, xmax=32)
plt.axvline(x=9, ymin=0, ymax=32)
plt.text(10, 10, 'Driving Factors')
plt.text(2,10,'Linkage Factors')
plt.text(2,4, "Autonomous Factors")
plt.text(10,4,'Dependent Factors')
#plt.savefig('micmac.png')
plt.show()
I figure looks Okay but there are certain annotations overlapped for example, see label 'F15' and 'F18' on 1st quadrant, there must be labels 'F3','F7','F15' instead of 'F15' and 'F5','F6','F9','F10','F13' instead of 'F18'
Output I need like this:
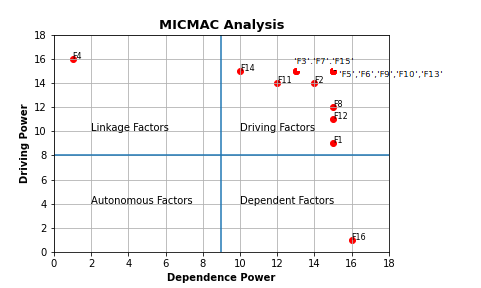
CodePudding user response:
There may be several approaches, create a data frame for the annotation, group by column value and list the indexes. Set annotations in the created data frame. In this data example, more strings overlap, so we change the offset values only for the indices we do not want to overlap.
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import io
data = '''
"Driving Power" "Dependence Power"
F1 9.0 15.0
F2 14.0 14.0
F3 15.0 13.0
F4 16.0 1.0
F5 15.0 15.0
F6 15.0 15.0
F7 15.0 13.0
F8 12.0 15.0
F9 15.0 15.0
F10 15.0 15.0
F11 14.0 12.0
F12 11.0 15.0
F13 15.0 15.0
F14 15.0 10.0
F15 15.0 13.0
F16 1.0 16.0
'''
prom = pd.read_csv(io.StringIO(data), delim_whitespace=True)
x = prom['Dependence Power']
y = prom['Driving Power']
n = ['F1','F2','F3','F4','F5','F6','F7','F8','F9','F10','F11','F12','F13','F14','F15','F16']
prom = prom.reset_index(drop=False).groupby(['Driving Power','Dependence Power'])['index'].apply(list).reset_index()
plt.scatter(x, y, color="red")
plt.xlim([0, 18])
plt.ylim([0, 18])
for i,row in prom.iterrows():
offset = 0.2 if i == 8 else 0.4
plt.annotate(','.join(row['index']),
(row['Dependence Power'], row['Driving Power']),
xytext=(row['Dependence Power'],row['Driving Power'] offset),
fontsize=8)
# for i, txt in enumerate(n):
# plt.annotate(txt, (x[i], y[i]), fontsize=8, rotation=0)
plt.ylabel('Driving Power', fontweight='bold')
plt.xlabel('Dependence Power', fontweight='bold')
plt.title("MICMAC Analysis", fontsize = 13,fontweight='bold')
plt.grid()
#axis lines
plt.axhline(y=8, xmin=0, xmax=32)
plt.axvline(x=9, ymin=0, ymax=32)
plt.text(10, 10, 'Driving Factors')
plt.text(2,10,'Linkage Factors')
plt.text(2,4, "Autonomous Factors")
plt.text(10,4,'Dependent Factors')
#plt.savefig('micmac.png')
plt.show()