I am attempting to scrape data through multiple pages (36) from a website to gather the document number and the revision number for each available document and save it to two different lists. If I run the code block below for each individual page, it works perfectly. However, when I added the while loop to loop through all 36 pages, it will loop, but only the data from the first page is saved.
#sam.gov website
url = 'https://sam.gov/search/?index=sca&page=1&sort=-modifiedDate&pageSize=25&sfm[status][is_active]=true&sfm[wdPreviouslyPerformedWrapper][previouslyPeformed]=prevPerfNo/'
#webdriver
driver = webdriver.Chrome(options = options_, executable_path = r'C:/Users/439528/Python Scripts/Spyder/chromedriver.exe' )
driver.get(url)
#get rid of pop up window
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#sds-dialog-0 > button > usa-icon > i-bs > svg'))).click()
#list of revision numbers
revision_num = []
#empty list for all the WD links
WD_num = []
substring = '2015'
current_page = 0
while True:
current_page = 1
if current_page == 36:
#find all elements on page named "field name". For each one, get the text. if the text is 'Revision Date'
#then, get the 'sibling' element, which is the actual revision number. append the date text to the revision_num list.
elements = driver.find_elements_by_class_name('sds-field__name')
wd_links = driver.find_elements_by_class_name('usa-link')
for i in elements:
element = i.text
if element == 'Revision Number':
revision_numbers = i.find_elements_by_xpath("./following-sibling::div")
for x in revision_numbers:
a = x.text
revision_num.append(a)
#finding all links that have the partial text 2015 and putting the wd text into the WD_num list
for link in wd_links:
wd = link.text
if substring in wd:
WD_num.append(wd)
print('Last Page Complete!')
break
else:
#find all elements on page named "field name". For each one, get the text. if the text is 'Revision Date'
#then, get the 'sibling' element, which is the actual revision number. append the date text to the revision_num list.
elements = driver.find_elements_by_class_name('sds-field__name')
wd_links = driver.find_elements_by_class_name('usa-link')
for i in elements:
element = i.text
if element == 'Revision Number':
revision_numbers = i.find_elements_by_xpath("./following-sibling::div")
for x in revision_numbers:
a = x.text
revision_num.append(a)
#finding all links that have the partial text 2015 and putting the wd text into the WD_num list
for link in wd_links:
wd = link.text
if substring in wd:
WD_num.append(wd)
#click on next page
click_icon = WebDriverWait(driver, 5, 0.25).until(EC.visibility_of_element_located([By.ID,'bottomPagination-nextPage']))
click_icon.click()
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.ID, 'main-container')))
Things I've tried:
- I added the WebDriverWait in order to slow the script down for the page to load and/or elements to be clickable/located
- I declared the empty lists outside the loop so it does not overwrite over each iteration
- I have edited the while loop multiple times to either count up to 36 (while current_page <37) or moved the counter to the top or bottom of the loop)
Any ideas? TIA.
EDIT: added screenshot of 'field name'
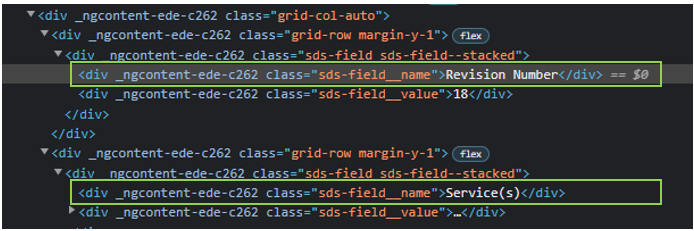
CodePudding user response:
I have refactor your code and made things very simple.
driver = webdriver.Chrome(options = options_, executable_path = r'C:/Users/439528/Python Scripts/Spyder/chromedriver.exe' )
revision_num = []
WD_num = []
for page in range(1,37):
url = 'https://sam.gov/search/?index=sca&page={}&sort=-modifiedDate&pageSize=25&sfm[status][is_active]=true&sfm[wdPreviouslyPerformedWrapper][previouslyPeformed]=prevPerfNo/'.format(page)
driver.get(url)
if page==1:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#sds-dialog-0 > button > usa-icon > i-bs > svg'))).click()
elements = WebDriverWait(driver, 10).until(EC.visibility_of_all_elements_located((By.XPATH,"//a[contains(@class,'usa-link') and contains(.,'2015')]")))
wd_links = WebDriverWait(driver, 10).until(EC.visibility_of_all_elements_located((By.XPATH,"//div[@class='sds-field__name' and text()='Revision Number']/following-sibling::div")))
for element in elements:
revision_num.append(element.text)
for wd_link in wd_links:
WD_num.append(wd_link.text)
print(revision_num)
print(WD_num)
- if you know only 36 pages to iterate you can pass the value in the url.
- wait for element visible using webdriverwait
- construct your xpath in such a way so can identify element uniquely without if, but.
console output on my terminal: